PC Plus HelpDesk - issue 261
 |
This month, Paul Grosse gives you more
insight into some of the topics dealt with in HelpDesk.
|
 |
HelpDesk
Just what is 'Crippleware'
Many of these terms have been around for years but for those people who are not entirely sure what they mean:
If the restriction is with time, it might be that it accumulates files at an alarming rate and the user has no way of controlling them. With saving, the files might be horrendously large or insecure; with printing, it could be that the writer of the program had no idea how to interface effectively with printer drivers. With limits such as 100 spreadsheet cells or one word processor page, it could be that there are serious issues with memory or speed. The rule of thumb is that, if there are features that are crippled, you need to ask why they have gone to the trouble of doing it and, why don't they want you to see or use those features? |
 In
computing, you come across many different terms -
'freeware', 'shareware', 'postcardware' and so on - but
you might find some programs referred to as
'Crippleware'?
In
computing, you come across many different terms -
'freeware', 'shareware', 'postcardware' and so on - but
you might find some programs referred to as
'Crippleware'?Moving Windows in KDE and GNOME
In this way, for example, you can be working on a piece of writing on one desktop, processing images for it on another and surfing the web on a third, all with your email browser occupying the full screen on a fourth. If someone comes along and wants you to edit a document (or find out how high a score you can get in Frozen Bubble), you just switch to an empty desktop and work there - or however many you need. As a computer journalist, I work in this way and when
I switch to a Windows environment, it seems positively
claustrophobic in comparison. |
 However, one thing you need to be able to do
is to move your windows from one desktop to another. However, one thing you need to be able to do
is to move your windows from one desktop to another.Normally, right-clicking somewhere on the border or title bar will make a drop-down menu appear and moving to another desktop is one of the options. Alternatively, you can drag a window over the edge of
the desktop into the next one and if you are using the 3D
desktops from Beryl or Compiz (right, on SuSE 10.2), the
desktop cube revolves when this happens. |
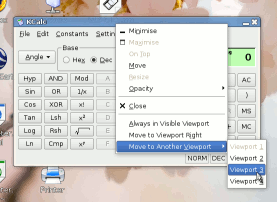
 However, if you have the Launch Pager on
your panel, you can drag a window from any desktop and
drop it into any other - as in the screenshot. However, if you have the Launch Pager on
your panel, you can drag a window from any desktop and
drop it into any other - as in the screenshot.You don't need to have either of them as the current desktop. |
 The
multiple-desktop environments in KDE, Gnome and a number
of other GUIs make life a lot easier - allowing the user
to organise their work better, multi-task and increase
productivity. The user is able to switch to another
desktop to handle an immediate job and then just switch
back to the original job when necessary.
The
multiple-desktop environments in KDE, Gnome and a number
of other GUIs make life a lot easier - allowing the user
to organise their work better, multi-task and increase
productivity. The user is able to switch to another
desktop to handle an immediate job and then just switch
back to the original job when necessary.Automatic quote replacement in OpenOffice.org Writer
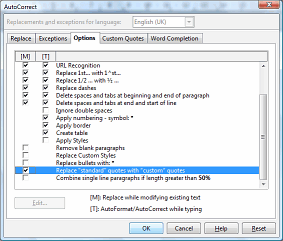
If you use OpenOffice.org (or Word, for that matter), you might find that it has the habit of changing the standard primes (' and ") for quotes so you end up with '6's, '9's, '66's and '99's instead of what you want. The smart quote substitution in OOo Writer is quite good at *English and American quotes, even when they are parenthetic and mixed with apostrophes. However, if you do a lot of typing that has little speech and includes angles or times - such as astronomical reports - or imperial measurements that include feet and inches, you would probably be better off keeping them the way you type them. To edit the defaults for when you are typing, click on 'Tools', 'AutoCorrect...' and on the 'Custom Quotes' tab, uncheck the 'Replace' checkboxes for each and then click on 'OK'. If you want to change other automatic replacements or custom quotes when editing later, click on the 'Options' tab before you click on 'OK' and edit the options at your will.
|
 If you
need your quotes to remain as primes, you need to stop
automatic quote replacement.
If you
need your quotes to remain as primes, you need to stop
automatic quote replacement.Setting a program's priority
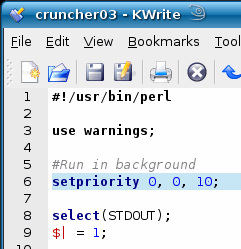
The reason that the other programs run as though the long-running program is not there is because, as far as the other programs are concerned, it isn't there. Computers do not possess inertia so you can switch from one process to another and back so that they appear to run at the same time. On the right, you can see the processor is loaded up
to the limit with a lower priority program and then,
around three quarters of the way through, another program
is started. It takes up the processing power that it
needs and the other program simply makes way for it. In
this way, the new, higher priority program runs as though
the other one was never there. |
 Normally, pretty much all of the programs
that you run will have the same priority and they will
compete with each other for processor time on an even
playing field. Normally, pretty much all of the programs
that you run will have the same priority and they will
compete with each other for processor time on an even
playing field.However, you can be more flexible than that. Some programming languages such as Perl and C will allow you to set the priority of the program so that when you run it, it will take all of the processor power there is but if anything with a higher priority (programs that aren't as nice) wants the processor, it can use it. The normal programs that the user runs, such as the GUI, word processor and so on, will all have priority over it and therefore run at almost their normal speed - the lower priority program isn't starved of processor time completely. By running the long-term program with a lower priority, you can ensure that you won't be locked out of normal work for several days by it. |
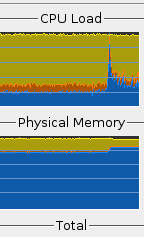 It is
possible to run a program continuously for several days,
taking all of the processor's available power, without it
getting in the way of other programs that are running on
the computer. This is how it can be done
It is
possible to run a program continuously for several days,
taking all of the processor's available power, without it
getting in the way of other programs that are running on
the computer. This is how it can be doneSorting enormous listsIf you collect data for some reason, you can find yourself in a position of having to sort the data. For small amounts of data, you might be tempted to use a spreadsheet - these are graphical and can use sort routines but there are limits. Spreadsheets are useful for sorting files but sifting out duplicates can be an annoyance. The main problem is that you are usually limited to some power of two lines, either 8192 or 65536 which is still short and even if you did have a larger spreadsheet, it would be overkill for this job. There is an easier way and it's free. Perl is designed, amongst other things, to process long strings and is used, for example, in chromosome analysis where you might like to find certain sequence of DNA bases in a gene, so it is quite capable handling a log file with a million lines in it. Here, you will find a couple of programs that demonstrate how easy it is to do this type of processing (Windows and UNIX versions).
The key lines are where each log file line (in a scalar called '$a') is split by spaces into an array (called '@z') and then the first element of this array is saved in an associative array (called a 'hash') called %h as follows... $h{$z[0]} = $a;
@kl = sort (keys (%h)); ...which puts the sorted key list into an array that is then accessed sequentially. If you just wanted to sort out the list without eliminating any duplicates, you would just use an array and sort that instead of using the hash. This type of programming is useful if you want to look at things like the number of user agents in your web server log file and so on. So, let's look at that... |
 ...which
stores the whole line using the hex code to sort it and
eliminating any duplicate keys. After this, the keys are
all sorted with the line...
...which
stores the whole line using the hex code to sort it and
eliminating any duplicate keys. After this, the keys are
all sorted with the line...Extracting UserAgent strings from log filesA typical log file records a fair amount of data on each transaction that a web server makes. Each line is one transaction and the fields for each line are all separated by spaces. Here is an example...
The part we are interested in is field 9. With the spaces that have gone before it and field 1 counting as zero, the first part of field 9 is element 11 like so...
So, let's look at the whole program (written step by step so you can see what is going on - at the end, you will see it in only 12 lines). You can see the files by clicking here.
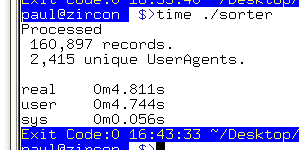
As for the speed of this program, you can run it with the 'time' command and as you can see from the screenshot, with real log data, a 160,000 record log file produced just over 2,400 unique UserAgents in nearly 5 seconds. The type of output from this program looks like
this... |
||||||
138 "-" 4 "Avant Browser (http://www.avantbrowser.com)" 3 "BlackBerry7130e/4.1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 VendorID/109" ... 1 "DataCha0s/2.0" 140 "FDM 2.x" 6 "Factbot 1.09" 1 "GetRight/6.3" 4644 "Googlebot-Image/1.0" ... 2 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Sky Broadband; InfoPath.2)" 13 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Smart Explorer 6.1; (R1 1.3); .NET CLR 2.0.50727)" 13 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; TARGET HQ; .NET CLR 1.1.4322; InfoPath.1; .NET CLR 2.0.50727)" 53 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Tablet PC 1.7; .NET CLR 1.0.3705; .NET CLR 1.1.4322)" ... 1 "Mozilla/5.0 (Windows; U; Windows NT 6.0; sv-SE; rv:1.8.1.5) Gecko/20070713 Firefox/2.0.0.5" 29 "Mozilla/5.0 (X11; U; FreeBSD i386; en-US; rv:1.8.1.4) Gecko/20070629 Firefox/2.0.0.4" 7 "Mozilla/5.0 (X11; U; Linux i586; en-US; rv:1.8.1.3) Gecko/20070310 Iceweasel/2.0.0.3 (Debian-2.0.0.3-1)" 1 "Mozilla/5.0 (X11; U; Linux i586; en-US; rv:1.8.1.4) Gecko/20061201 Firefox/2.0.0.4 (Ubuntu-feisty)" 181 "Mozilla/5.0 (X11; U; Linux i686 (x86_64); en-GB; rv:1.8.1) Gecko/20061023 SUSE/2.0-30 Firefox/2.0" and so on. If you don't want the frequency data or the console output, you can omit lines 3, 6, 11, 12, 13, 15, the '$h{$y}' term in line 21, 24, 25, 26 and 27. Also, we can use the default scalar with split instead of converting $_ to $a and also use the default whitespace in split instead of " " (this cuts out 4 characters - this is programming) so we can remove line 8 and modify line 9 like so...
It's now only 16 lines long and some of those only have a closing brace on them. Out of curiosity, if this was a competition to see how few a number of lines we could get this down to (and we weren't bothered about speed), we could; eliminate line 2, using instead '-w' on the first line; eliminate $j by condensing lines 6 and 7; and, remove the foreach loop at the end by joining @kl with a new line escape sequence and then eliminate @kl all together by condensing those two lines like so...
... and now it is down to 12 lines. However, this does take just over 9 seconds to run using the same log file. |
 The only
place this falls down is where a non-standard proxy
introduces spaces in the string that it sends as a
referrer.
The only
place this falls down is where a non-standard proxy
introduces spaces in the string that it sends as a
referrer.CGI scripting languageThere are a number of languages that will run CGI (Common Gateway Interface) scripts but some are safer than others. Whilst most people will be able to write a script that can take input that is expected and process it well, the job of hardening a script so that it is secure enough to allow the public access to it, is another thing all together. The public includes honest users, just surfing the Internet with their browsers and, dishonest users who might not even be using a browser at all. This latter group will try to bombard your scripts with values that are out of range, the wrong type of variable, strings that are too long, other scripts and so on. They will try to hack your database and plant stuff on your site.
Unlike other languages, Perl won't bail out because someone sent it a floating point or a string that was 60,000 bytes long when it was expecting an integer. It is well worth getting to know Perl because most of the web uses it - it also pops up in unexpected places as well such as puzzle program generators and the game Frozen Bubble. And yes, I have got past level 70. |
 A language
that is outstanding in its ability to withstand this type
of abuse is Perl (
A language
that is outstanding in its ability to withstand this type
of abuse is Perl (