PC Plus HelpDesk - issue 233
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk and HelpDesk
Extra
|
 |
HelpDesk
Tightening up your firewallBy default, most firewalls will allow through any connection that originates on the inner network or LAN. The problem with this is that anything that has managed to break into a network and has taken a foothold can initiate a connection through the firewall to anything on the Internet that it can attack. This can be achieved by users opening email attachments and by users browsing the Internet with Scripts being allowed to run. The easiest way of stopping this is to disable the firewall rule that says that any connection started on the inside of the firewall (the LAN side) will be allowed through.
You should normally find this as the next to last rule in the list. Note that you should never disable the last rule (that is to say the last one above) as doing so effectively allows through any traffic that has not been denied explicitly in the preceding rules ie, all of those flaws in the Windows flat security trust model that allows Windows to work will be opened for anybody to 'share all of your pictures and files'. One thing that you may well notice once all of these programs have been closed off is that ports will have to be allowed explicitly. Port 80 (HTTP) and 110 (POP3) being allowed to have access to the Internet from the LAN will be fairly obvious but there are plenty of others, depending upon what you have running (if you have your own SMTP server, you shouldn't be allowing 110 to be open from the LAN as that becomes redundant). One problem you might encounter is FTP (21) which can work with port 21 as the control channel and another, arbitrary channel for the data. The problem is that the data channel is opened by the server at the other end and this is blocked off by the firewall as it is an externally initiated connection. With FTP, you can connect so that it all goes down port 21 and that will work or, you have a firewall that looks at the data content of the packets for port 21 and recognises that it should then let through externally initiated traffic from that address on the specified port. |
More about catching hackersIf there is anything that it irresistible to a
black-hat hacker, it is a server that has not yet been
fully patched. These machines usually represent an opportunity to use resources that could allow them to invade another machine or send spam - the limits are with their imagination - and if done correctly, none of it would be traceable back to them. So, why are IIS servers prone to being hacked? Are they easier to hack or is it something else? (or both?) It is possible to make an IIS server reasonably secure so, without getting bogged down in a flame war about whether IIS or Apache (or anybody else's server) is better, let's look at why. Over a period of time, both paid-for and free servers
have vulnerabilities exposed. If a vulnerability is
fairly obscure - say for example, only if you use a
particular type of database and cookies at the same time
- then a patch or a work-around will do. If there is a
gaping hole, allowing administrator or root access, then
that tends to have a little more say on whether a new
version is issued. This has the knock-on effect that free servers will on average (50 per cent of the way through the version's life time) have fewer vulnerabilities in them than paid-for servers. It does take a short time to patch a server but if somebody knows what they are doing, they will patch it fairly quickly. In a given population of admins putting up servers, there is a possibility that the server will be up when Google spiders it and the default page will end up on Google. Of course, a few minutes/hours later, the server will be fully patched and be displaying its proper website (even though it shouldn't have been up before it was patched any way - their existence on Google demonstrates that they were). The result of this is that if anybody wants to find a server that is more likely to have vulnerabilities on it, they can use a search engine to find the default page of a paid-for server. If that link has a server that now has a proper website on it then it is of little consequence but if the default pages are still there, there is a chance that it is a server that has been installed by somebody who is still close to the bottom of the learning curve and therefore the machine is still likely to be vulnerable. So, how do black-hat hackers find such machines? There are sites on the Internet that will tell you what you can find out for yourself just by using Google. If, in the search string, you type 'allintitle:' and then the string of characters that are in the title page you are looking for, you will get a list of such pages on the Internet. So, who would want to look for default IIS pages? People who want to break into vulnerable machines is a pretty large group (relatively speaking). In addition to this, you need to know how the rest of the world sees you so you need to take a look yourself. So, let's catch some of them at it. Instead of having a vulnerable bought server with its default page, we can have something that just looks like it is one... If you are running something other than a Windows machine, you can set up a virtual host (this is easy enough to do on Apache and it has the advantage that it is not IIS) with a default page (click here) that has a spiderable but otherwise invisible link to it (a small, transparent image so that a spider will pick it up but normal users will not) on a web page that is spidered by Google. If you use DynDNS, you can set up a convincing sounding domain name for it for free. Once it is spidered, it will go into Google's cache and wait until someone types those magic characters into the search bar. Once somebody does do that and then clicks on it, the search string will end up in your server's access log file with a line that contains the following... "http://www.google.com/search?hl=en&lr=&q=allintitle %3AWelcome+to+Windows+2000+Internet+Services" ... and you will also end up with a series of lines, one for each of the images (I find that this happens several times each day). There is a possibility at this stage that it could be just someone who has heard about doing this who is just seeing what happens - or, it could be someone trying to take advantage of an unconfigured, unpatched server. If, following that, you then get a number of other lines, asking for things that are not there, then that could well be someone who is testing out the server to see what is available. These could include... "GET /localstart.asp HTTP/1.0" "GET /iisadmin.asp HTTP/1.0" "GET /iissrtat.asp HTTP/1.0" "GET /iisstart.asp HTTP/1.0" "GET /iishelp HTTP/1.0" "GET /iishelp/ HTTP/1.0" "GET /iisadmin/default.asp HTTP/1.0" "GET /iishelp/iis/default.htm HTTP/1.0" ... and they should all be typed in by hand (ie, no referrer) unless it is done using a script at their end (you can tell to some extent by looking at the times in the log). The above activity is closer to black-hat hacking as it shows that the person at the other end has the requisite knowledge. So, what next? "GET /../../cmd.exe HTTP/1.0" "GET /../../notepad.exe HTTP/1.0" The above two lines (taken from a real log along with all of the others above) show that the same user also has the requisite intent. This is an offence as describe under the Computer Misuse Act. They are trying to go up two directory levels (out of the server root and into the system at large - they are assuming that the server root is a known number of steps away from where they want to go so again, they are displaying the requisite knowledge but clearly they are not aware that it is not a Windows system) and then, in the case of cmd.exe, open up a command shell so that they can perform arbitrary commands on the attacked system and, in the case of notepad.exe, open up a text editor so that they can edit or create arbitrary files. If you chroot Apache, they can't even do that if they do break the server (OpenBSD's Apache server does this by default and is part of their default installation). There is a way of telling that the server that is really sending out the pages is not an IIS server but the fact that the people who try to hack default page sites like this continue to do so shows that they are not experienced or knowledgeable enough to know what that is or how to do it. So, we've caught a black-hat hacker's activity on a server and they have displayed to us that they have the requisite knowledge and the requisite intent. Next, we take their IP address from the server log, open up a shell prompt and type... whois www.xxx.yyy.zzz where www.xxx.yyy.xxx is the IP address. This should give us their ISP's netblock information, along with an abuse@ address. Then, we email the section of the log and a polite note to their ISP. If they are in the UK, then you can notify the police (High Tech Crime Unit) as well. One point worthy of note is that if someone has taken over a machine and using that to look at your site, the IP address in your log will be the compromised machine. Still, they need to know that they have a compromised machine. The above extracts from the log were from an attacker (or compromised machine) in India. If you want to set up your own IIS default page honey pot, you can use the files in the files directory on this SuperDisc instead of trawling the Internet and ending up with me reporting you to your ISP. |

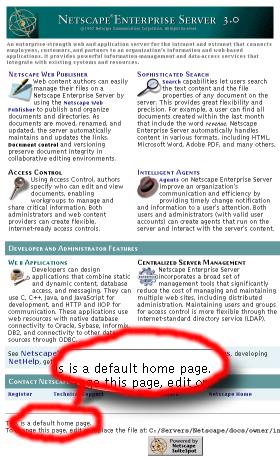 If people have to pay
for a server, they don't want to have to fork out every
few weeks or months for a new one. Free servers can be
issued as new versions more frequently. So, if you are
paying for a server, you expect something that is
revolutionary whereas free servers tend to be
evolutionary.
If people have to pay
for a server, they don't want to have to fork out every
few weeks or months for a new one. Free servers can be
issued as new versions more frequently. So, if you are
paying for a server, you expect something that is
revolutionary whereas free servers tend to be
evolutionary.HelpDesk Extra
Opening up a command line in:Windows 98SE
Here, I have put it in the programs menu but you will
probably find it in the 'Accessories' sub-menu. Wherever
you find it, the thing you are looking for is usually
called 'MS-DOS Prompt'.
The first three buttons across the top allow you to select, copy and paste text. The fourth allows you to make it full screen. If you do this and want to get back to the original, windowed version (ie, you can see the other windows on the system) all you need to do is press [Alt][Enter] - note that this toggles it so it can be used to get into full screen as well. The next button is the properties button and the one
after that, allows processes that you create in this DOS
box to run in the background. That means that other
things can happen as well. The last button allows you to
select which font you want to use in the display. There
are a number to choose from but whether they are bitmap
or TrueType, they are all mono-spaced. Windows XP
When you do that, you get a menu that looks like the
following... This gives you a similar set of options to the Windows
98SE DOS-Box but in addition, you can specify the colours
of the text and background. Linux
Alternatively, you can right-click on the Panel Menu
bar at the bottom, from the drop-down list, select 'Panel
Menu', 'Add', 'Application Button', 'SuSE', 'System',
'Shells', 'Bash' or 'Panel Menu', 'Add', 'Application
Button', 'SuSE', 'System', 'Terminal Applications',
'Konsole' depending on which you want or which
distribution you are using and this will put the shell
icon on your panel menu - the terminal icon in the
screenshot. |
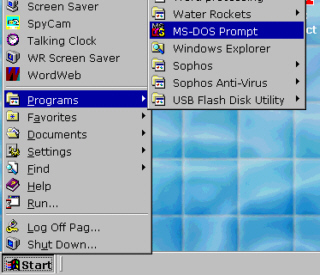 Click on 'Start',
'Programs' and then, it depends upon where you have put
it (if you have moved it around) or where it has been
left.
Click on 'Start',
'Programs' and then, it depends upon where you have put
it (if you have moved it around) or where it has been
left.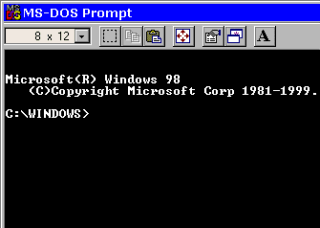 When you do find it,
it should look like this...
When you do find it,
it should look like this... In Windows XP, click
on 'Start', 'Programs', Accessories', 'Command Prompt'
and you will get the following...
In Windows XP, click
on 'Start', 'Programs', Accessories', 'Command Prompt'
and you will get the following...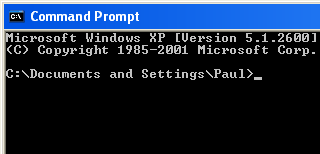 To get any options on
this, you need to right-click on the 'Command Prompt'
window decoration at the top.
To get any options on
this, you need to right-click on the 'Command Prompt'
window decoration at the top. 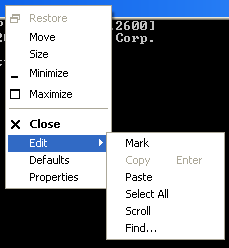
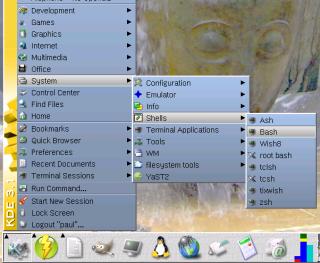 Click on the Menu
Icon and then 'System', 'Shells' and then the command
shell you want (usually 'Bash').
Click on the Menu
Icon and then 'System', 'Shells' and then the command
shell you want (usually 'Bash').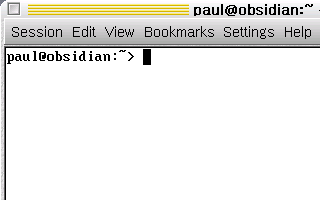 The shell should look
like this...
The shell should look
like this...
File system basicsWindows (98 and XP)In theory, the Windows file system is quite simple: each disk partition has a drive letter assigned to it so that the first hard disk drive letter is 'C:', the next is 'D:' and so on. As this is the real file system used on Windows/Dos machines, this is what you will see when you use a command prompt on the system. This is not to be confused with the virtual file system that you see when you look at a directory tree in Windows Explorer.
You can see that here, Windows pretends that the Desktop is the root of the file system, from which comes 'My Computer', 'My Documents', 'Internet Explorer' and so on. On the desktop, you should see these listed along with any files or links that you have but this is not the real story. If you have a look at the Windows Explorer address bar, you will be able to see that if you have drive 'C' selected (as here) then the path in the address bar is 'C:\' and not, Desktop\My Computer\C:\' as you would expect. If you click on 'Desktop' in the left pane, that is what appears in the address bar. This also happens with 'My Computer, 'My Documents', (Don't try it with Internet Explorer or it might close that window and open up the web browser - typing 'Desktop' into the address bar of that will only bring back the single-paned version of Windows Explorer) 'Network Neighbourhood', 'Recycle Bin' and 'My Briefcase' although none of these are prefixed with 'Desktop\'. However, if you click on a directory that you have
created such as WebLinks in this example, the address bar
reveals the location of the Desktop directory and that it
is just a mapping created by Windows as opposed to a real
entity - in this case
C:\WINDOWS\Profiles\[UserID]\Desktop\AVIs as I have
profiles turned on.
Windows XPThe only real difference is that with Windows XP, the Desktop root directory is in 'C:\Documents and Settings\[UserID]\' instead of 'C:\WINDOWS\Profiles\[UserID]\' The only problem that all of this creates for the
operating system (as opposed to the user who needs to
know which set of user directories he/she is looking
through) is that Windows likes to present itself as the
current user's set of options which is okay until you
allow people to log on through a terminal. Normally,
users log onto Windows XP and as they switch user, the
system fiddles it so that each one looks like the current
user. Unices (Linux, *BSD et cetera)
The Unix-like file system is a lot simpler as there is a root (/ not to be confused with /root which is the name and home directory of a special user) in one of the partitions and all other partitions are mounted within that. Here, /nas has NAS storage mounts in it and /boot has the startup files in it for the system. There are a number of other partitions in this system - you can put extra partitions in /home as you need them or /srv and so on. Basically they are as follows:
On some systems, lan, media, nas, opt, or srv will be in other places - lan and nas won't exist, srv will be in var as www. This latter is the web root if you are running a server - it is kept in /var/www along with all of the Apache and Perl bits so that Apache can change its root directory (chroot) to the server root and its user to one without any privileges. In the unlikely event that the server is taken over, any user that has managed to do that will end up with only /var/www as their root directory so they will not be able to roam around the system and they will not be able to chroot out as they are not root - in effect, they are in a jail and have accomplished nothing. As a user without privileges, they cannot even deface the website. Viewing the current directoryIn Windows, type dir and you will see the contents of the current directory In Linux/Unix, list the contents of the current directory by using ls There are options with all of these and you can find them out by looking at the manual pages which in Windows means you type ... help dir ... and in the Unices ... man ls ... or ... man 1 ls |
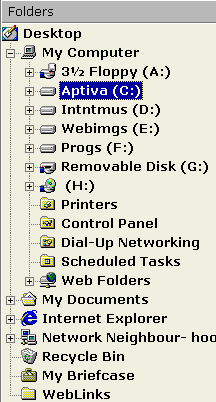 The following
screenshots are all taken from Windows 98SE but the same
structures and problems exist with Windows XP.
The following
screenshots are all taken from Windows 98SE but the same
structures and problems exist with Windows XP.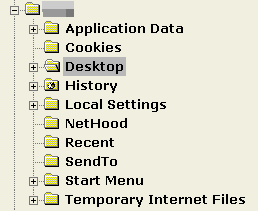 If you go to that
directory and click on 'up one level' (the folder icon
with the left/upwards pointing arrow) you will be taken
back to the Desktop but instead, if you click on the
address bar and delete back to and including the
backslash (so that you have
C:\WINDOWS\Profiles\[UserID]\Desktop) then that directory
will be expanded and you can see something along the
lines of the structure on the right.
If you go to that
directory and click on 'up one level' (the folder icon
with the left/upwards pointing arrow) you will be taken
back to the Desktop but instead, if you click on the
address bar and delete back to and including the
backslash (so that you have
C:\WINDOWS\Profiles\[UserID]\Desktop) then that directory
will be expanded and you can see something along the
lines of the structure on the right. With the Unices,
nothing is altered between users in a multiple-user
environment and each one has their own home directory. As
the (Unix-like) system has to change nothing to keep up
any illusion (mainly because there is no illusion) the
users can switch in a keystroke ([Ctrl][Alt][Fn] where n
is a number from 7 to 9 for the local monitor (for SuSE
with KDE although this varies for different OSes). Also,
processes that any particular user has, will keep on
going whilst the local monitor is being used by another
user. So...
With the Unices,
nothing is altered between users in a multiple-user
environment and each one has their own home directory. As
the (Unix-like) system has to change nothing to keep up
any illusion (mainly because there is no illusion) the
users can switch in a keystroke ([Ctrl][Alt][Fn] where n
is a number from 7 to 9 for the local monitor (for SuSE
with KDE although this varies for different OSes). Also,
processes that any particular user has, will keep on
going whilst the local monitor is being used by another
user. So...Moving around the file systemIf you want to move around the file system, you need to change the directory that you are in. You can do this either by specifying the directory you need to go to in relative terms (relative to the current directory) or in absolute terms (the whole directory path to the new current directory). In Linux/Unix, there is only one file system with all of the partitions mounted within it but with DOS, there is a file system for each mounted partition. So, if your current directory is D:\some\path\ and you want to change to whatever the current directory on drive C: is, all you need to do is to type... C: ... and it will change. Note that if you want to change back to drive D:, and type 'D:', you will end up back in 'D:\some\path\'. In both Windows and Linux/Unix, you use the CD command. Note that Windows uses a '\' (backslash) to delineate directories whereas all other operating systems use '/' (called a 'slash'. It is not called a 'forward slash' despite the efforts of the BBC to change its name. I suppose the point is that if it is called a 'slash' the BBC will think that people will sit around giggling every time it is mentioned. If you doubt this, I can tell you from personal experience that when I did a piece for radio, many years ago, they edited out the word 'bum') AbsoluteWindowscd c:\windows\system32 Linux/Unixcd /home/paul/Desktop RelativeWindows and Linux/Unixcd .. In the latter case, the directory above the one you are in can be reached by using '..' - to go the other way, you need to specify the name of the directory you want to go into. If you had a directory in the current one called 'temp' (you can find the names of directories in the current directory by entering ls or dir), you can cd to it by typing cd temp If, to get to temp, you needed to go up one level and then back down one, ie the structure is #-work-#-temp
|
#-current
... and you are in current, then you can combine the two as follows (first Windows and then Linux/Unix)... cd ..\temp cd ../temp With many commands that take a file name, you can specify a relative or absolute directory path. Note also that the paths on web servers (whether they are running on Windows or one of the Unices) all have '/' to delineate the directory and file names. This is because the Internet runs on Unix and not on Windows. |
Creating/deleting directoriesYou can create a new directory (in Windows or Linux/Unix) by typing mkdir and then the directory name like so ... mkdir test You can then cd into it and out of it. To remove it, just type rmdir and its name (when you are not in it - if you are doing it relatively as in the example, you need to be in its parent directory). rmdir test |
Creating filesYou can create a file by a number of means - usually with a program that generates file output or with a text editor - but basically, you need to make a file have some data in it and if you just want to test out your command line skills, you can do this easiest by redirecting a directory listing to a file. RedirectionRedirection takes the output of a file and directs it to some sort of output device which could be a file. In addition to this, you can also specify an input source such as a file. To do this, you start off with the command name on the command line and then you can if you want, specify the input file. Next, specify the output file. There are two symbols that are used to let the OS know what you want to do and they are < (input from...) and > (output to...) and the command line is as follows: command [< input stream] [> output stream]. So, if you want to create a file from your directory listing, you would do the following (Windows then Linux) dir > listing.txt ls > listing.txt If you want to append a file, you should use two '>'s like so... dir >> listing.txt ls >> listing.txt PipingPiping is similar to redirection only instead of redirecting an output stream to a file or similar, you are directing it to another program so the input of one program is the output of the previous program. Like redirection, there is a special symbol - the split vertical bar '|' (which is often not split at all). To take a directory listing and pipe it to another program that looks for a particular string in a line and then outputs those lines you could do the following (Windows XP then Linux) ... dir /N | find "54" ls -a | grep dr ... which, in the first case, looks for files in a 'new style' directory listing that have the number 54 in them and, in the second case, look for files that have the string 'dr' in a full listing (ie, those that are directories that can be read by their owner and those with a 'dr' in the file name). You can pipe several commands together like this and as they all flow from the left to the right, all separated with the '|', they are fairly easy to edit if you use a shell that can look at and edit previous shell commands by pressing the 'up' arrow key such as the default DOS shell or Bash in Linux/*BSD/Unix. |
Viewing and editing filesYou can look at the contents of a file by using the 'more' command (Windows and Unix). This takes a file name and displays it a screen-full at a time and you press the [spacebar] to see the next screen. For example... more myfile.txt The distinct disadvantage of this is that you can only move forward through a file. There is a better way under Linux/Unix and that is to use 'less' like so... less myfile.txt ... and this will allow you to move forwards and backwards through the file using the up/down arrow keys - 'q' to exit. To edit a file in Windows and then in Linux/Unix, type edit myfile.txt vim myfile.txt There is more on using edit and vim on the Internet. |
Some nifty command line commandsTo get help on any of these commands, (say 'at' for example) just ask for the relevant help manual on the system. This can be done on Windows and Linux/Unix as follows... help at man at Note that in Linux/Unix, there are a number of manuals and you can specify which one you want to see. Often a command like 'at' will be written like 'at (1)' where the one is a reference to the manual number. You can put this in the manual command line request as follows... man 1 at As you might have guessed, one thing that you can do on XP as well as on Linux/Unix is set a command to run at a particular time either in absolute or relative terms. This is done with the 'at' command. To be fair, it has to be said that the most useful command line functions are on Linux/Unix (although the best help pages are on OpenBSD). LocalSome that can be done on the local machine include: 'w' (find out who is on the system and what they are doing: paul@obsidian:~> w 11:28:10 up 26 days, 2:14, 5 users, load average: 0.59, 0.62, 0.62 USER TTY LOGIN@ IDLE JCPU PCPU WHAT root :0 05Jun05 ?xdm? 2days 0.01s -:0 root pts/0 05Jun05 26days 0.00s 2.77s kdeinit: kwrited paul pts/1 05Jun05 26days 0.00s 3.98s kdeinit: kwrited paul pts/2 11:12 1.00s 0.15s 0.04s w paul :1 05Jun05 ?xdm? 2days 0.03s -:1 'who am i' (in case you forget who you are logged in as): paul@obsidian:~> who am i paul pts/2 Jul 1 11:12 (amethyst.gem) 'cal' which returns a calendar of the current month (or others by adding parameters - September 1752 is interesting because it didn't have 30 days in it paul@obsidian:~> cal
July 2005
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
paul@obsidian:~> cal 9 1752
September 1752
Su Mo Tu We Th Fr Sa
1 2 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
'top' shows you the top processes (in terms of the amount of processor time they are using) top - 11:43:12 up 26 days, 2:29, 5 users, load average: 0.68, 0.64, 0.59
Tasks: 173 total, 1 running, 172 sleeping, 0 stopped, 0 zombie
Cpu(s): 21.2% user, 5.2% system, 0.0% nice, 73.6% idle
Mem: 255896k total, 248364k used, 7532k free, 26440k buffers
Swap: 459136k total, 214668k used, 244468k free, 41520k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ Command
2846 root 18 0 8140 5900 3868 S 17.3 2.3 1717:14 ksysguard
20406 root 16 0 5248 3928 1800 S 3.9 1.5 216:21.57 appletproxy
2858 root 15 0 672 556 332 S 2.9 0.2 1111:53 ksysguardd
16440 paul 16 0 1052 1052 792 R 2.3 0.4 0:00.36 top
3 root 15 0 0 0 0 S 0.0 0.0 0:00.21 kapmd
4 root 34 19 0 0 0 S 0.0 0.0 0:05.31 ksoftirqd_CPU0
5 root 15 0 0 0 0 S 0.0 0.0 2:02.74 kswapd
6 root 15 0 0 0 0 S 0.0 0.0 0:00.00 bdflush
7 root 15 0 0 0 0 S 0.0 0.0 0:00.23 kupdated
8 root 15 0 0 0 0 S 0.0 0.0 0:05.61 kinoded
10 root 25 0 0 0 0 S 0.0 0.0 0:00.00 mdrecoveryd
13 root 15 0 0 0 0 S 0.0 0.0 0:15.71 kreiserfsd
149 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lvm-mpd
884 root 15 0 256 232 160 S 0.0 0.1 2:46.24 syslogd
887 root 15 0 1236 288 272 S 0.0 0.1 2:53.79 klogd
(press 'q' to quit.) 'uptime' tells you how long the computer has been up and running paul@obsidian:~> uptime 11:47am up 26 days 2:33, 5 users, load average: 0.69, 0.64, 0.59 'ifconfig' ('ipconfig' in Windows) lets you know what is going on with the network interfaces. You will need to substitute-user ('su') to root to use this though. You do that just by entering su and then the root password (note that in OpenBSD, you will have already to be a user that is a member of the group 'wheel'. Also note that you should not log in as root either, only as a normal user and then su to root). obsidian:/home/paul # ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:00:0E:E4:D7:FF
inet addr:192.168.168.200 Bcast:192.168.168.255 Mask:255.255.255.0
inet6 addr: fe80::200:eff:fee4:d7ff/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:11712030 errors:0 dropped:0 overruns:0 frame:0
TX packets:13316523 errors:0 dropped:0 overruns:1 carrier:0
collisions:0 txqueuelen:100
RX bytes:3057165231 (2915.5 Mb) TX bytes:4273415386 (4075.4 Mb)
Interrupt:11 Base address:0x1000 Memory:f4200000-f4200038
NetworkIn a networking environment, you can log onto another machine using telnet or ssh (you Windows has a client for telnet or you can get 'Putty' and there are ssh clients for Windows as well) You use them the same as each other, ie telnet 10.231.16.94 ssh 10.231.16.94 But, one thing to remember is that on telnet, all of the traffic is in the clear so it is only suitable on a network that is trusted in all respects - no wlan, no Internet and so on. Also, it is remembering that if you have a machine firewalled (which you should have), you need to open the appropriate port on the telnet server or ssh server and, if you can, restrict access to it from just local network machines (although this does not make it safe because it is possible to take over another machine on the local network and then use that to telnet into the one you have just opened. Google 'port numbers' for a full list. 'host' ('nslookup' on Windows) will look up the ip address of a domain name and get the dns information of an ip address. paul@obsidian:~> host www.pcplus.co.uk www.pcplus.co.uk has address 212.113.202.52 'whois' retrieves the netblock information. paul@obsidian:~> whois 66.249.87.104 OrgName: Google Inc. OrgID: GOGL Address: 1600 Amphitheatre Parkway City: Mountain View StateProv: CA PostalCode: 94043 Country: US NetRange: 66.249.64.0 - 66.249.95.255 CIDR: 66.249.64.0/19 NetName: GOOGLE NetHandle: NET-66-249-64-0-1 Parent: NET-66-0-0-0-0 NetType: Direct Allocation NameServer: NS1.GOOGLE.COM NameServer: NS2.GOOGLE.COM Comment: RegDate: 2004-03-05 Updated: 2004-11-10 OrgTechHandle: ZG39-ARIN OrgTechName: Google Inc. OrgTechPhone: +1-650-318-0200 OrgTechEmail: arin-contact@google.com # ARIN WHOIS database, last updated 2005-06-30 19:10 # Enter ? for additional hints on searching ARIN's WHOIS database. 'ping' lets you know if a machine is there and how quick the connection is. WindowsC:\>ping -n 10 66.249.87.104
Pinging 66.249.87.104 with 32 bytes of data:
Reply from 66.249.87.104: bytes=32 time=20ms TTL=246
Reply from 66.249.87.104: bytes=32 time=17ms TTL=246
Reply from 66.249.87.104: bytes=32 time=17ms TTL=246
Reply from 66.249.87.104: bytes=32 time=20ms TTL=246
Reply from 66.249.87.104: bytes=32 time=28ms TTL=246
Reply from 66.249.87.104: bytes=32 time=17ms TTL=246
Reply from 66.249.87.104: bytes=32 time=18ms TTL=246
Reply from 66.249.87.104: bytes=32 time=17ms TTL=246
Reply from 66.249.87.104: bytes=32 time=17ms TTL=246
Reply from 66.249.87.104: bytes=32 time=27ms TTL=246
Ping statistics for 66.249.87.104:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 17ms, Maximum = 28ms, Average = 19ms
(Note that since Code Red, many people block pings from Windows machines (yes, you can tell)) Linuxpaul@obsidian:~> ping -c 10 66.249.87.104 PING 66.249.87.104 (66.249.87.104) 56(84) bytes of data. 64 bytes from 66.249.87.104: icmp_seq=1 ttl=247 time=19.2 ms 64 bytes from 66.249.87.104: icmp_seq=2 ttl=247 time=18.9 ms 64 bytes from 66.249.87.104: icmp_seq=3 ttl=247 time=17.0 ms 64 bytes from 66.249.87.104: icmp_seq=4 ttl=247 time=16.5 ms 64 bytes from 66.249.87.104: icmp_seq=5 ttl=247 time=16.8 ms 64 bytes from 66.249.87.104: icmp_seq=6 ttl=247 time=16.7 ms 64 bytes from 66.249.87.104: icmp_seq=7 ttl=247 time=16.1 ms 64 bytes from 66.249.87.104: icmp_seq=8 ttl=247 time=16.5 ms 64 bytes from 66.249.87.104: icmp_seq=9 ttl=247 time=16.2 ms 64 bytes from 66.249.87.104: icmp_seq=10 ttl=247 time=20.4 ms --- 66.249.87.104 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9090ms rtt min/avg/max/mdev = 16.135/17.469/20.450/1.432 ms |