PC Plus HelpDesk - issue 253
 |
|
 |
HelpDesk
|
 Remembering commands
Remembering commandsCHROOT
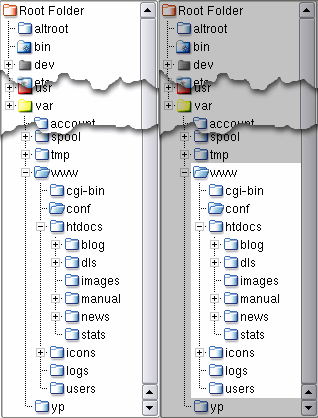
When you chroot a process, instead of being able to 'cd ..' upwards until it can see the 'Root Folder' and then explore anywhere it likes such as /etc, /home and so on, it can, as in the example on the right, only go up as far as what we know here as /var/www. This has the effect of /var/www/htdocs/blog being seen as /htdocs/blog by the chrooted program. So, any absolute paths need to have the modified path instead. Also, you cannot see /bin so anything from there that needs to be seen needs to be copied over to within the chroot and so on. If you are writing a program in Perl, you might have some lines like the following... #### This program's location ####
# if you don't want to chroot the process, make the string empty...
#
# $chrootloc "/usr/local/srv/";
# or, if not chrooted,
# $chrootloc "";
#
$chrootloc = "/usr/local/srv/";
#### Log file's location ####
# Detailed log location (relative to the chroot).
# Note (1), start this with a '/' but don't end it with one.
# eg $logloc = "/log"; # is all right, just make sure that there
# is a directory and that this program has write access to it.
#
# Note (2), if you are running this on a system that does not have
# chroot, or you don't want to run is as chroot, just use the path
# from the real root for the log location ($logloc) and make the
# $chrootloc chroot location a null string.
#
# $logloc = "/log";
# or, if not chrooted,
# $logloc = "/usr/local/srv/log";
#
$logloc = "/log";
#### Chroot the process ####
if ( length($chrootloc) > 0) {
chroot $chrootloc;
};
So, the server is configured to be provided with a path string if it is going to be chrooted and if it is, the log file path has to be the shortened version for it to make sense. |
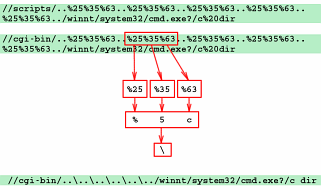
Hidden codesIf you run a server, you should look through your server logs at regular intervals anyway but sometimes you might find peculiar strings like '//cgi-bin/..%25%35%63..%25%35%63' and so on. These are usually strings generated by people - usually known disrespectfully as a 'Script-Kiddies' - running a script to try to break into your system. You often find that these 'people' (for want of a better word) will get to your site via some link or other (if you store your logs in combined log format, the referrer will be logged as well) and then a few seconds or minutes later, that same IP address will send maybe a dozen requests per second - all of them different - trying out various hacks. These attacks on your system are genuine. They are all things that work on somebody's server or they are extrapolated from such attacks. However, instead of somebody with a knowledge of how systems work, trying to break into your system, it is some kid (or somebody with the mental age of a kid) just running a script. These lists of attacks are added to by genuine, black-hat hackers, who know that by giving these Internet Noddys something that might work, they can create enough background noise to hide what they are up to. Script kiddies might think that they are up to having a laugh and possibly even getting away with a little bit of knowledge but really, they are aiding and abetting real criminals.
Normally a two-digit hex value preceded by a per cent sign will be converted to the ASCII equivalent and if it is not permitted, filtered out. Here, they have made sure that when this is done once, there is still a hex preceded by a per cent sign. In this case, '%25' turns into '%' and the other two values form hexadecimal characters. So, '%25%35%63' forms '%5c' which, when transformed again, forms a backslash which, on DOS/Windows system, is a directory path delimiter. So, '//cgi-bin/..%25%35%63..%25%35%63' becomes '//cgi-bin/..\..\' and as double-dot is the parent directory, they are attacking the server by specifying a valid directory then hoping to work their way back up the directory tree, out of the 'server root' and into the rest of the file system. You can see from the diagram that they intend to test out the hack by getting a directory listing. This is a Windows-specific hack. Make sure your system is up to date or use a more secure OS (possibly a server OS such as UNIX, Linux, OpenBSD...). |
 The hack
on the right is based on ASCII codes for characters that
normally are either not permitted in http addresses or,
as they are here, being hidden so that any program that
does the conversion once, will still not see what is
intended.
The hack
on the right is based on ASCII codes for characters that
normally are either not permitted in http addresses or,
as they are here, being hidden so that any program that
does the conversion once, will still not see what is
intended.Keyboard Shortcuts in KDE
On Windows, you would use [F3] to find the next item in a document search and there is no reason why you should expect to use anything else - after all, it is part of the PC culture - isn't it? Well, not necessarily so. You might find that having tweaked it and forgotten that you tweaked it, it was [Ctrl][G]. Who would use that? Mac users use [Ctrl][G] to find the next item in a document search. So, this is how to fix it... Open up Control Center, and click on 'Regional &
Accessibility' then 'Keyboard Shortcuts'. |
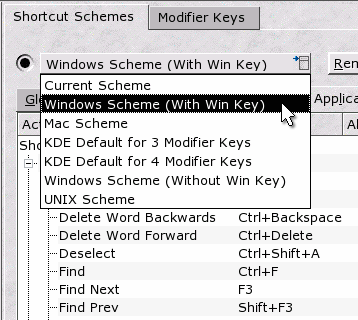 You will
now see where you can select your own, personal set of
shortcuts - you can make your own schemes if you really
want to. You will
now see where you can select your own, personal set of
shortcuts - you can make your own schemes if you really
want to.These shortcuts will work on your own account so if some other user wants their own set, they can have them without interfering with yours. If you click on the combo that says 'Current Scheme', you will see a number of schemes that will suit users from Mac, Windows, UNIX and other systems. Choose the one you want and you will see the shortcuts appear. If you select one of the Windows schemes then click on the 'Application Shortcuts' tab, you will see your [F3] appear next to 'find next' which is the way you like it. Now - if only we could get hold of a UNIX keyboard with all of those wonderful modifier keys ... |
 If you
have just arrived at the door of Linux and you have been
trying everything out (as one tends to do) then you might
have made tweaks that you cannot relocate very easily.
One of these (potentially, at least) is changing the
keyboard shortcut scheme.
If you
have just arrived at the door of Linux and you have been
trying everything out (as one tends to do) then you might
have made tweaks that you cannot relocate very easily.
One of these (potentially, at least) is changing the
keyboard shortcut scheme.Blur - Which?
If you have used the pre-Windows 98 version of Windows
Paint, you can probably remember RLE as a way of making
bitmap ('.BMP') files substantially shorter if there were
large areas of one colour. In the case of paint, it
looked along the line of pixels and counted how many were
the same. You can look at RLE Gaussian blur in the same
way because that is basically how it works. Note that you
can also use this as a way of remembering which Gaussian
blur method to use. |
|||||||||||||||||||||
 You can
check the speeds out for yourself by blurring both with a
large and a small blur radius, a large photographic image
(say 8M pixels) with each method and then repeating the
experiment for a similarly sized digram. You can
check the speeds out for yourself by blurring both with a
large and a small blur radius, a large photographic image
(say 8M pixels) with each method and then repeating the
experiment for a similarly sized digram.In the table below, I took a photographic image and used the two blur methods with two sizes of blur (on a 1.8GHz PC). I then flood-filled the image and drew some sharp-edged lines all over it and repeated the experiment. You can see which is better and how much worse RLE gets for the large blurs but especially in the photograph. Note that the blur algorithms used in The GIMP are
updated from time to time. |
|||||||||||||||||||||
|
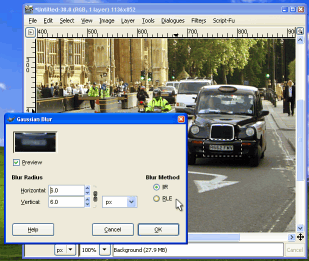 If you
have used the blur on the Gimp, you might have noticed
that there is a choice of Gaussian blur - 'IIR' and 'RLE'
so, which should use use? Also, the end results of each
of these methods is identical so why bother with two?
If you
have used the blur on the Gimp, you might have noticed
that there is a choice of Gaussian blur - 'IIR' and 'RLE'
so, which should use use? Also, the end results of each
of these methods is identical so why bother with two?Specialist or Spam?One problem you might have if you use an email footer that says the same thing every time is that your perfectly honest and legal emails keep on getting blocked by mail filters. This all started last century when many Internet users encountered the problem when AOL decided to block all email containing certain words. All of a sudden, breast cancer groups found themselves blocked and spammers quickly learned that they could surround their key words with other text. At the time, I was writing for a computer security magazine, reviewing network security tools including a mail filter. As a result, I developed the 'Scunthorpe test' to assess mail filters - interested to see if that great Yorkshire town would be filtered out by the product I was reviewing (it was filtered out). Now, with many spammers trying out commercial email for alternative medications, the term 'specialist' is being blocked because it contains the sub-string 'cialis' which, we all know, is only found in spam (as in 'Canter and Siegel' rather than 'Hormel Foods'). There are plenty of other genuine words - usually place names such as Penistone, Middlesex and so on - that also contain words that are likely to be found in lists of banned words. The solution therefore is to substitute the offending word and thank the spammers for their bit in making the Internet just that little bit less usable for the rest of us. |
SIM back-upSo, you got a brand new mobile phone for Christmas. All you have to do is copy all of your telephone numbers from your old SIM to your new one - and it would probably be a good idea to make a backup copy of them too.
The devices that you insert your SIM card in are usually small USB devices that you can purchase for around £10 in the high-street. Insert the card in the reader and then into your computer and start the program. Select phone numbers and load them onto your PC. You can now save them as a backup file that you can load onto your new card. With your new card in, you can also add new numbers
using your computer keyboard number pad which is a lot
easier than using the pitiful thing on the phone - no
matter how advanced a phone it is supposed to be. |
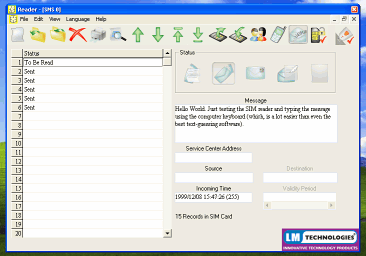 There are,
of course, other things on your SIM card as well such as
stored messages. There are,
of course, other things on your SIM card as well such as
stored messages. |
 You can
type in new messages using all of your computer keyboard
which, let's face it, is a lot easier than being a two
thumb typist (no wonder that the txt language evolved and
kids nowadays cannot spell). You can
type in new messages using all of your computer keyboard
which, let's face it, is a lot easier than being a two
thumb typist (no wonder that the txt language evolved and
kids nowadays cannot spell).When you have finished,
back-up, then save your messages, numbers and so on onto
your SIM and re-insert your phone's brain. |
 With your
SIM in place, along with the battery, you can switch it
on and your messages will be there. With your
SIM in place, along with the battery, you can switch it
on and your messages will be there.Oh, for a PS2 socket on a mobile phone. |
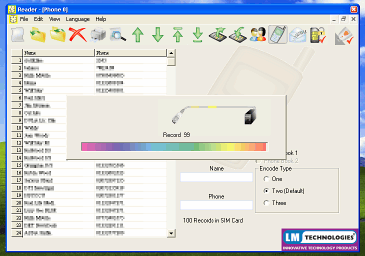 First of
all, you need to download your numbers from your old
card.
First of
all, you need to download your numbers from your old
card.Solarisation
You sometimes see it in archive footage of nuclear explosions where the xray fluorescence of the atmosphere produces a sun-like sphere that over exposes the film. On the right, you can see genuine solarisation in a digital camera (a Vivitar Vivicam 3720 in this case) produced by pointing the camera at the Sun. On the right of that is the actual pixel-for-pixel part of the image. The magenta ring around it shows that the green layer
on this camera is more susceptible to solarisation than
the other layers. |
 This
image, again, is real solarisation only this time, it is
taken at sunset. The cyan layer overexposes first this
time because there is so much more red in a sunset due to
filtering of the Sun's light by the Earth's atmosphere. This
image, again, is real solarisation only this time, it is
taken at sunset. The cyan layer overexposes first this
time because there is so much more red in a sunset due to
filtering of the Sun's light by the Earth's atmosphere.In the darkroom, you can create an effect called 'pseudo-solarisation' or the Sabattier effect. This is done by flooding the film with a light, part-way through its development when some pigment has already been formed, usually on a print. The existing pigment protects the image and the part of the image where there is not much pigment developed get plenty of exposure. From personal experience, it is fairly easy to do once you have the amount of exposure right. In essence, the brightest thing in the image has the
density range inverted. |
 Nowadays,
with digital image processing, you can do this a lot
easier and with a great deal of control. Nowadays,
with digital image processing, you can do this a lot
easier and with a great deal of control.In the images
above, the brightest thing in the sky is the Sun which
over-exposes quite nicely. Here, however, the sky is
supposed to be the brightest thing so we will find out
where in the image the sky finishes and invert that. |
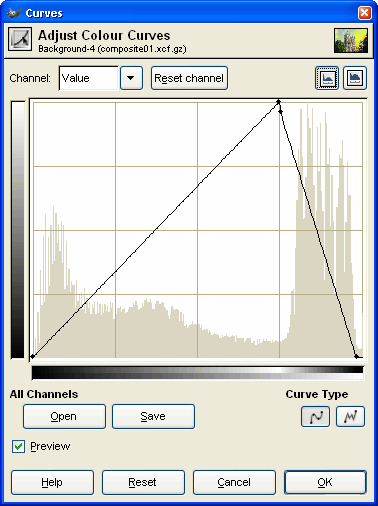 In the
GIMP, open the levels dialogue box and then decide on a
point at which the density scale will invert. In the
GIMP, open the levels dialogue box and then decide on a
point at which the density scale will invert.You can find out where the sky densities are by dragging the mouse over it and seeing where the sampled density line is within the range. You can see in the screen-shot on the right that I have chosen a point where the main range of densities of the sky start. Drag the right-hand point down to the bottom and add a point at the top at the correct density. The curve is smoothed so you might need to add a second point just to get it to a point at the top. Also, you can clip the top and bottom of the density range by dragging the end points away from the extremes of the graph. And, you can add extra points to the graph to modify
the shape of the curve until you have it the way you
want. |
 As the sky
changes hue slightly in this range, not only does it
become negative but the hue is reflected as well. As the sky
changes hue slightly in this range, not only does it
become negative but the hue is reflected as well.Note that in addition to the sky, some highlights of Westminster Cathedral's stonework is also in this range. If you want to eliminate this, just mask them out. |
 Solarisation,
as the name might suggest, is the gross overexposure of
normal camera film - often caused by the Sun.
Solarisation,
as the name might suggest, is the gross overexposure of
normal camera film - often caused by the Sun.Fingerprint access control
Fingerprint biometrics devices fall roughly into two areas: chip and optical:
Basically, TIR tells you where a finger is in contact with the surface of the device but using other techniques over a period of time can iron out many of the methods of spoofing prints. The device in the photograph (from Lumidigm http://www.lumidigm.com/ ) uses five wavebands of light and polarisation in addition to time related artefacts such as bleaching, making TIR redundant in this case. Also, being weather-proof (this fingerprint reader has an on-board heater so your finger won't stick to it at its lower working temperature of -20 Celcius) and having an Ethernet connection allows it to be used for access control in external or other hostile environments. In the demonstration in the photograph above, water was being poured over it continuously. A TIR unit would normally fail to detect points of contact for a fingerprint because the refractive index of water is so close to that of the moisture/grease/finger that a finger produces. The thing to remember is that security of any sort does not make it impossible to break into something or somewhere - it only makes it more difficult. If you employ a hundred people and need external access control then you might find the Lumidigm device is right but if you want to control access to a computer inside a secured building, a desktop or keyboard-based sensor - even a TIR unit - might be more appropriate because there are other layers of security already in place. |
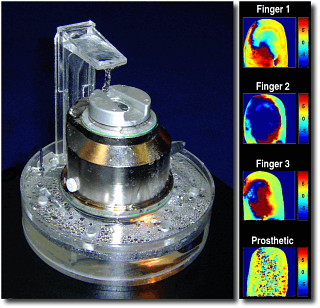 You can
use biometrics to control access, not only to computers,
but also to buildings and other areas - different types
are more suited to some applications than others.
You can
use biometrics to control access, not only to computers,
but also to buildings and other areas - different types
are more suited to some applications than others.Total Internal Reflection (TIR)
The refractive index is simply the ratio of the speed of light in a vacuum divided by the speed of light in the medium in question. This also varies according to wavelength so, for the reason that it is fairly easy to reproduce what is effectively monochromatic light from sodium vapour, the sodium 'D' line is used. In the diagram on the right, you can see how refractive index is measured. A semi-circular prism has a light source shine on it and where that light hits the centre of the flat face, the angle of incidence is known because the entry of the light into the prism is normal to the surface. The light travels through the medium and is reflected completely internally and is then observed by an optical device pointing at the same centre point. The prism can be rotated around this centre point so that the angle of total internal reflection can be observed as a transition from total internal reflection to no internal reflection (looking down the microscope shows a light and dark area - you just rotate the prism until this transition matches a mark next to it in the view). The angle is known so the refractive index can be calculated (it is inscribed on a calibrated vernier scale so you just have to read off the refractive index). If you place a liquid on the surface, this changes the refractive index of one of the media and thus changes the angle at which total internal reflection occurs. This is useful if you want to identify a pure liquid or if you have, say a reactor, which contains a mixture of liquids and you can tell how much of one there is because its refractive index is significantly different to that of the others - you would create a number of mixtures in the lab, find their refractive indices and plot them on the graph. You would then place a few drops of reactor sample liquid on the block, wait for it to get to the right temperature (the prism block has a water pipe running around it so you can control the temperature thermostatically) then measure the refractive index. Using the fact that placing a denser medium than air
changes the angle of total internal reflection, you now
use this to create an image of where something is in
contact with the medium as long as the medium is both
flat and smooth. |
 And, this
is how optical fingerprint readers work. And, this
is how optical fingerprint readers work.Incident light is reflected internally but when you put the ridge of a finger in contact with it, the light travels into the finger (where it is dispersed) instead of being reflected internally. This image is picked up and used to make the fingerprint reader work. Unfortunately, it only picks up where something is in contact with it and it doesn't know what that is. This is why this type of reader is particularly prone to silicone, latex and gelatine fingerprint spoof attacks. |
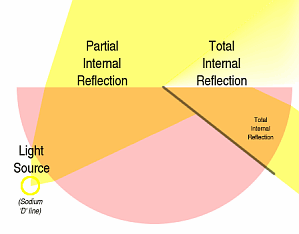 If you
have ever swam under water and looked upwards, you will
have seen that below a certain angle, all of the light is
reflected from under the surface and you can only see
light from above the surface if you look in a tighter
angle looking upwards. This angle depends upon the
refractive index of the water. So, what is refractive
index?
If you
have ever swam under water and looked upwards, you will
have seen that below a certain angle, all of the light is
reflected from under the surface and you can only see
light from above the surface if you look in a tighter
angle looking upwards. This angle depends upon the
refractive index of the water. So, what is refractive
index?EBCDICGood quality web servers are written for a number of environments and if you have looked through your httpd.conf file, you might have noticed a section that looks similar to this... # EBCDIC configuration: # (only for mainframes using the EBCDIC codeset, currently one of: # Fujitsu-Siemens' BS2000/OSD, IBM's OS/390 and IBM's TPF)!! # The following default configuration assumes that "text files" # are stored in EBCDIC (so that you can operate on them using the # normal POSIX tools like grep and sort) while "binary files" are # stored with identical octets as on an ASCII machine. # # The directives are evaluated in configuration file order, with # the EBCDICConvert directives applied before EBCDICConvertByType. # # If you want to have ASCII HTML documents and EBCDIC HTML documents # at the same time, you can use the file extension to force # conversion off for the ASCII documents: # > AddType text/html .ahtml # > EBCDICConvert Off=InOut .ahtml # # EBCDICConvertByType On=InOut text/* message/* multipart/* # EBCDICConvertByType On=In application/x-www-form-urlencoded # EBCDICConvertByType On=InOut application/postscript model/vrml # EBCDICConvertByType Off=InOut */*
EBCDIC (Extended Binary Coded Decimal Interchange Code) dates back to the days of punched cards and pre-dates ASCII by nearly half a decade. Anybody who has used a Port-A-Punch (nostalgia ain't what it used to be) will be familiar with this but for everybody else... Each card has 80 columns of 12 rows with each character occupying one column. The third row down and onwards are labelled 0 to 9. For letters of the alphabet, two holes are used, one in the top three rows - a-i, j-r and s-z - with the second hole for each character in rows 1 to 9 thus, 'b' has a hole in the top row and one in the row labelled '2'. For the third set, 's' has a hole in the row labelled '2' so that 'z' falls in the row labelled '9' and we don't end up with too many holes adjacent to each other. EBCDIC is actually an 8-bit character encoding (ASCII
is only seven) and the punched card patterns for letters
and numbers fall directly into it. Unfortunately, the
non-contiguous nature of the alphabet produces
programming problems going from 'i' to 'j' or 'r' to 's'.
Apart from that, there is nothing wrong with it even
though it is completely incompatible with ASCII and there
are a number of different versions. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| If you want to see what EBCDIC looks like when you
try to view it in ASCII, look at the files in this
directory. You can convert files from ASCII to EBCDIC and vice versa using the 'dd' command (available for UNIX and Windows). The 'dd' command breaks the rules for command line arguments in that instead of using switches like '-s 1024' where you have a switch preceded by a dash, then the value, in 'dd', you have 's=1024' instead. So, to convert the file 'ascii.html' to 'ebcdic.html', you use... dd conv=ebcdic if=ascii.html of=ebcdic.html ...or (for ibm alternative EBCDIC)... dd conv=ibm if=ascii.html of=ibm_ebcdic.html where 'if' is the input file name and 'of' is the
output file name. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
SP = Space; BL = Bell; BS = Backspace;
VT = Vertical Tab; HT = Horizontal Tab; |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| You can see that the layout of the letters and
numbers in EBCDIC and on the punched card are very
reminiscent of each other. EBCDIC is the native language on IBM and Fujitsu-Siemens mainframes and is current. For a webserver, text files are stored in EBCDIC but the server must convert these to ASCII which is why it's mentioned in the httpd.conf file. If your server uses ASCII is the native language, the EBCDIC directives are ignored anyway. If your ISP is running an EBCDIC machine, it is their problem and not yours. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Whilst you
are probably not running a mainframe, it is nice to know
what something is so, what is EBCDIC?
Whilst you
are probably not running a mainframe, it is nice to know
what something is so, what is EBCDIC?PermissionsThe permissions on UNIX-like systems are actually quite easy to understand so here is a look at the basics... On a UNIX or UNIX-like system, examples of which are OpenSolaris, Linux, the BSDs and many more, files and directories have access permissions based upon three groups of users: Owner; Group; and, World.
For directories:
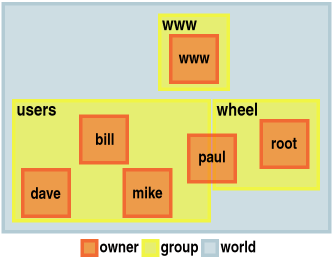
Directory permissions are listed like 'drwxr-xr-x' where the leading 'd' means a directory. File permissions for a Perl script might look like '-rwxr-x--x': the owner can read, write and execute it, users in the same group can read it and execute it but everybody else can only execute it. If you are the owner of a file or directory, you can change its permissions using 'chmod' but the owner cannot change the owner of a file. However, there is an all-powerful user called 'root' which can do pretty much anything including change the owner of a file/directory using the 'chown' command. In order to become root ('root' isn't permitted to log on remotely), a normal user has to use a command - 'su' or 'substitute user'. On many systems, any user can become 'root' just by knowing the 'root' password. However, on an OpenBSD machine (UNIX), you also have to be a member of the 'wheel' group - any user can be a member of more than one group but only 'root' can edit the '/etc/group' file. Whilst 'paul' can 'su' to 'root', 'mike', 'bill' and
'dave' cannot. If 'dave' wants to become 'root', he needs
to 'su' to 'paul' and then 'su' to 'root' so under this
regime, anybody who wants to break in needs to know a lot
more about the system along with more passwords and
UserIDs; or, have physical access. |
 Your
webserver will run as an unprivileged user called 'www'
or 'wwwrun' but it doesn't own any files therefore it
cannot change any permissions. Your
webserver will run as an unprivileged user called 'www'
or 'wwwrun' but it doesn't own any files therefore it
cannot change any permissions.If you have it 'chrooted' as well, anybody who manages to break into it cannot even undo the chroot (only 'root' can). Even if somebody with the root password managed to compromise the webserver, they could still not 'su' to 'root' because the user that the server runs as is not in 'wheel'. In other words, in OpenBSD, there is little if anything that they can do even if they do manage to break in. As a matter of interest, OpenBSD is secure in many other ways, putting security first in the default insallation. |
 For file
permissions:
For file
permissions: