PC Plus HelpDesk - issue 251
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk and HelpDesk
Extra
|
 |
HelpDesk
Phishy domain namesSometimes, you get emails that come from services that you are a member of and sometimes you get them from services that you are not. This is one such email From: "New MySpace Message" <cantrips@ezbaz.com> To: <########@###############> Subject: New message from Sarah on MySpace sent on Oct 06 17:20:00 -4 2006 Date: Sat, 07 Oct 2006 00:33:09 +0300 ... You've got a new song from Sarah on MySpace! Click here to hear your MySpace music: http://myspace.mp3shest.com/?reloc.cfm=6&id=89934 Click here to get 5-free songs downloaded to Your Space: http://myspace.mp3shest.com/?reloc.cfm=6&id=8993459183_5free ------------------------- At MySpace we care about your privacy. We have sent you this notification to facilitate your use as a member of the MySpace service. and, so on.
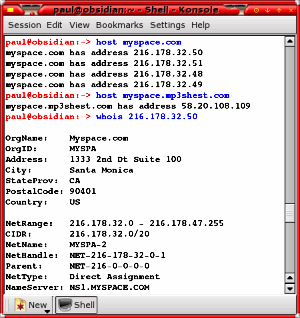
If you are on a UNIX-like system like Linux or BSD, you can just open up a console. Using 'host', you should get something like the following for 'www.myspace.com' and 'myspace.mp3shest.com'... paul@obsidian:~> host www.myspace.com www.myspace.com has address 216.178.32.51 www.myspace.com has address 216.178.32.52 www.myspace.com has address 216.178.32.137 www.myspace.com has address 216.178.32.48 www.myspace.com has address 216.178.32.49 www.myspace.com has address 216.178.32.50 paul@obsidian:~> host myspace.mp3shest.com myspace.mp3shest.com has address 221.4.246.3 This gives you individual addresses that those domain names link to. You can see that the first three octets are completely different but that on its own does not prove that they are not linked. In addition - and being a little more conclusive - we can look at the people who own the blocks of IP addresses. If we try 'whois' on one of the myspace IPs and on the suspect... paul@obsidian:~> whois 216.178.32.50 OrgName: Myspace.com OrgID: MYSPA Address: 1333 2nd Dt Suite 100 City: Santa Monica StateProv: CA PostalCode: 90401 Country: US NetRange: 216.178.32.0 - 216.178.47.255 CIDR: 216.178.32.0/20 NetName: MYSPA-2 NetHandle: NET-216-178-32-0-1 Parent: NET-216-0-0-0-0 NetType: Direct Assignment NameServer: NS1.MYSPACE.COM NameServer: NS2.MYSPACE.COM Comment: RegDate: 2006-05-22 Updated: 2006-05-22 OrgTechHandle: MYSPA-ARIN OrgTechName: MySpace NOC OrgTechPhone: +1-310-215-1001 OrgTechEmail: noc@myspace.com # ARIN WHOIS database, last updated 2006-10-06 19:10 # Enter ? for additional hints on searching ARIN's WHOIS database. paul@obsidian:~> whois 221.4.246.3 % [whois.apnic.net node-2] % Whois data copyright terms http://www.apnic.net/db/dbcopyright.html inetnum: 221.4.0.0 - 221.5.127.255 netname: CNCGROUP-GD descr: CNC Group Guangdong province network descr: China Network Communications Group Corporation descr: No.156,Fu-Xing-Men-Nei Street, descr: Beijing 100031 country: CN admin-c: CH455-AP tech-c: CH455-AP remarks: service provider mnt-by: APNIC-HM mnt-lower: MAINT-CNCGROUP-GD mnt-routes: MAINT-CNCGROUP-RR changed: hm-changed@apnic.net 20030108 status: ALLOCATED PORTABLE changed: hm-changed@apnic.net 20060124 source: APNIC route: 221.4.0.0/16 descr: CNC Group CHINA169 Guangdong Province Network country: CN origin: AS17816 mnt-by: MAINT-CNCGROUP-RR changed: abuse@cnc-noc.net 20060118 source: APNIC role: CNCGroup Hostmaster e-mail: abuse@cnc-noc.net address: No.156,Fu-Xing-Men-Nei Street, address: Beijing,100031,P.R.China nic-hdl: CH455-AP phone: +86-10-82993155 fax-no: +86-10-82993102 country: CN admin-c: CH444-AP tech-c: CH444-AP changed: abuse@cnc-noc.net 20041119 mnt-by: MAINT-CNCGROUP source: APNIC You can see now that the two are not related. It did, of course, turn out that this was just a phishing scam, trying to get the usual information from end users. It was, however, spammed quite aggressively and went out to many non-MySpace users.
You can open up a DOS box and use 'nslookup' instead of 'host'. Whois resources for Windows users...Even with Windows, you can still find 'whois' services
on the Internet if you know where to look. So, here's
where to look...
|
||||||||||||||||||||||||
 Tempting
though it might be to click on the link to
'mysapce.mp3shect.com' - especially with the bait of
getting several free mp3 songs as well, it would not be
wise to do so. This scam plays on the fact that many
people who use the Internet simply have no idea about how
any of it works. The senders of this email hope that its
recipients will see the 'myspace' and '.com' parts of the
domain name and think that this is the real thing - not
realising that 'myspace' is, in this case, a subdomain of
'mp3chest.com'.
Tempting
though it might be to click on the link to
'mysapce.mp3shect.com' - especially with the bait of
getting several free mp3 songs as well, it would not be
wise to do so. This scam plays on the fact that many
people who use the Internet simply have no idea about how
any of it works. The senders of this email hope that its
recipients will see the 'myspace' and '.com' parts of the
domain name and think that this is the real thing - not
realising that 'myspace' is, in this case, a subdomain of
'mp3chest.com'.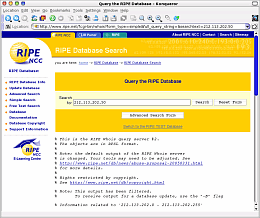 So, if you
are unfortunate enough not to have access to a computer
that runs UNIX, Linux, BSD and so on, what can you do
with Windows?
So, if you
are unfortunate enough not to have access to a computer
that runs UNIX, Linux, BSD and so on, what can you do
with Windows?Buffer Overflows/overruns
Essentially, the buffer is just a space where input data can be stored so that it can be used - there are several types of buffer but this is essentially what happens with an overflow. You can think of the buffer as a compiled variable - say, in this case is it a string that can be a maximum of 1,024 bytes long. The program counter trundles along at its own pace, reading commands and executing them until it gets to the jump command at the beginning of the buffer. Then, it jumps to where the end of the buffer and start processing again. That way, the processor only ever processes commands and never tries to process what is essentially data. The middle part of the diagram shows what happens normally. This could be a subroutine for taking a command or anything that uses user input - also known as tainted data. You might have a situation like this if this program was a server and the programmers had also written a client that would supply it with strings that were 1,024 bytes long or less. In this case, there would not be a problem with buffer overruns Many programming languages have no way of protecting themselves against tainted input and many programmers do not code with security in mind. This leads to a situation where somebody else could be using a program that they had written and they deliberately send your server a string that was, say, 1,536 bytes long. Without any checking of this, it would end up with 1,536 bytes being written into that variable. The extra 512 bytes replaces whatever is at the end of that variable, which might well be some program code - this 'data' will then be executed when the program jumps to the end of the buffer. With this in mind, some people craft the extra data as proper program code - ie, sending it machine code instructions so that your sever does what they want it to do - whether that is to crash your server (Denial of service attack, aka DoS attack); take it over so that they can use it to send spam; or, gain escalated privileges. In order to effect this, they will send long strings to a server until it breaks. Then, they will try to find out how it broke and then, they will have an idea of what programming they will need in order to do what they want. If that sounds a little far fetched, then it will surprise you to find out that that is what happens. So, whether you run Windows, Linux, BSD or anything else, in the updates you will often see patches for buffer overflows so it is worthwhile using them. |
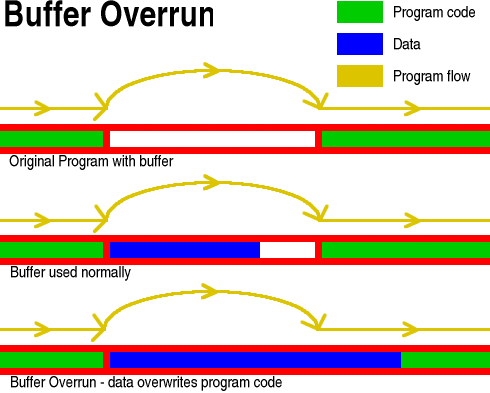 Buffer
overruns can be seen in security updates most of the
time. They happen when you have a buffer in a program
such as in the top part of the diagram on the right which
depicts a program with a buffer in it as a line of code
in memory.
Buffer
overruns can be seen in security updates most of the
time. They happen when you have a buffer in a program
such as in the top part of the diagram on the right which
depicts a program with a buffer in it as a line of code
in memory.Click to remove?
Should you? Unless you live close to the postal address of the sender or know someone who does so that you can pay them a visit, there is, unfortunately, no way of telling whether clicking on the link in the email would:
Therefore, I would say 'don't click on the link' - just delete it. In the UK, the Privacy and Electronic Communications Regulations (EC Directive) 2003 requires explicit prior consent to be given for commercial emails to individual subscribers. Many senders of emails will be sending them to addresses with domain names that end in '.com' but there are no limits to where these addresses will be and some will undoubtedly end up in the UK and therefore subject to the regulations. Interesting... |
 Many
times, you will see an email that will claim that you can
remove yourself from a distribution list just by clicking
on a link in the email.
Many
times, you will see an email that will claim that you can
remove yourself from a distribution list just by clicking
on a link in the email.
|
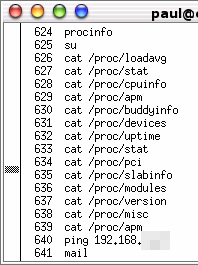 You can
see it's contents by typing 'history' at the command line
or, if you are not on a graphical CLI, you can pipe it to
less by typing 'history|less'. This is particularly
useful if you are wondering what you typed in order to
achieve something in particular a moderate time ago. You can
see it's contents by typing 'history' at the command line
or, if you are not on a graphical CLI, you can pipe it to
less by typing 'history|less'. This is particularly
useful if you are wondering what you typed in order to
achieve something in particular a moderate time ago.One thing to be aware of is that although your history file has '-rw-------' as its permissions, root can also read it. If root is someone other than yourself, can you really trust them? (hint ... no.) So, if you have ever typed your password on the command line by mistake (perhaps thinking that you had already issued a command that was waiting for it), it will be in there as well. .bash_history is a plain text file so you can either search through it in KWrite, remove any offending lines and then save the file or just delete it. |
 History in
BASH
History in
BASH
|
 The page
is written so that no particular coding is used and as a
result, you can specify which ranges of Unicode values
you use and which font and so on. The page
is written so that no particular coding is used and as a
result, you can specify which ranges of Unicode values
you use and which font and so on.To change the encoding, just right-click on the page and select the encoding you want. This all sounds as though it is really useful but in the same way that electricity can be used to power your computer or an electric chair, there is a negative side to this as well. |
| Many spammers and other senders of unwanted email
deliberately use these codes in order to obfuscate the
true identities of links in emails - thinking usually
correctly that the user will not bother to check them out
first. You will see, if you look at the source of the
unicode.html file, that the codes from 32 to 127 can be
written as Unicode values thus obfuscating their true
meaning. In addition, some malicious websites use them in an attempt to get though filtering proxies that would otherwise filter out their pages. Remember: '%73%65%78' will sell just about anything. |
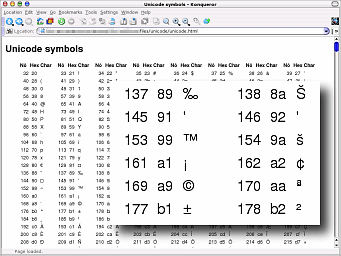 Dark side
of Unicode
Dark side
of Unicode
|
||||||||||||||||||
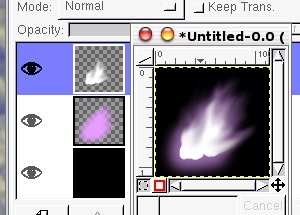 All you
need to do is to mimic the over exposed area and the
surrounding glow. This is simpler than it seems. All you
need to do is to mimic the over exposed area and the
surrounding glow. This is simpler than it seems.First of all, create a mask, say by using the Bezier curve selection tool. Next, create two new layers. Select one of them and fill the selected area with white. Next, select the other, grow it, blur it and then fill it with the flame colour you want. Next, use the smudge tool to spread out the flames and the glow as you wish - you should end up with something like the image on the right. |
||||||||||||||||||
 The other
emission spectrum in the image is from sodium. Off to the
left of the frame is a sodium street lamp. It is doing
two jobs here: The other
emission spectrum in the image is from sodium. Off to the
left of the frame is a sodium street lamp. It is doing
two jobs here:Firstly, of all, it is illuminating the steam and smoke from the fire; and, Secondly, it is casting an interference pattern across the image in a series of feint, concentric circles that you can see if you look carefully at the image on the right (the top one is straight from the image and the bottom one is enhanced to some degree). You can get a pattern like this quite simply with the GIMP by editing a gradient pattern so that it has a sinusoidal blending function and then creating the grading fill in a new layer using a radial gradient, dragging the mouse over only a short distance and allowing the GIMP to repeat the pattern for you. |
||||||||||||||||||
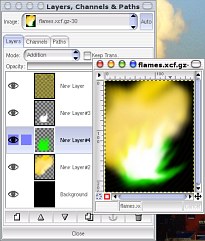 In files/flames/,
there is a flames.xcf.gz file that you can see on the
right. You can load this into the GIMP and have a play
around with it. In files/flames/,
there is a flames.xcf.gz file that you can see on the
right. You can load this into the GIMP and have a play
around with it.If you select the layer with the emission spectrum in it (green for copper in this case - pure, saturated green (#00ff00)), you can use the hue/saturation tool to change the element. Thus... |
||||||||||||||||||
|
 Flames on
film
Flames on
film



Migrating machines - recovering passwords
Your passwords will be encrypted wherever they are stored on your hard drive so, unless you know a program that you can use to crack them, you have a bit of a problem. But there is an easy way. All you need to do is to load KNOPPIX into the CD/DVD drive of your new computer and plug the Ethernet connection into the back of your Internet router along with your old machine. Now, boot up the machine with KNOPPIX on it and it will load into your RAM without writing anything to your hard drive. |
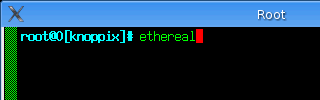 Next, open
up a root console and enter 'ethereal' -- the menus are
pretty much the same as on Windows XP so they are fairly
easy to find. The reason you need to do this from a root
console is that you are going to listen in on the network
which is a privileged action and normal users aren't
allowed to do this. Next, open
up a root console and enter 'ethereal' -- the menus are
pretty much the same as on Windows XP so they are fairly
easy to find. The reason you need to do this from a root
console is that you are going to listen in on the network
which is a privileged action and normal users aren't
allowed to do this. |
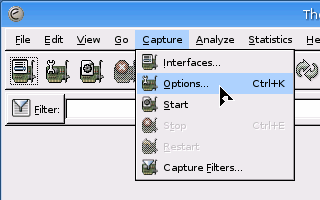 You should
now have Ethereal up and running as root. Next, you need
to capture the traffic on your network in what is called
'promiscuous mode'. You should
now have Ethereal up and running as root. Next, you need
to capture the traffic on your network in what is called
'promiscuous mode'.Click on 'Capture' and then 'Options...'. |
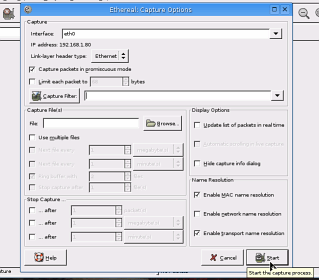 In the
Capture Options dialogue box, everything should be set
pretty much as you would need it any way so just click on
Start. In the
Capture Options dialogue box, everything should be set
pretty much as you would need it any way so just click on
Start. |
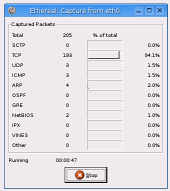 Once all
of this is in action, just run your email program and
your password will be passed across the network in the
clear. Once all
of this is in action, just run your email program and
your password will be passed across the network in the
clear.Ethereal will pick this up and you will be able to read it. Once you have sent/received your email, click on 'Stop'. |
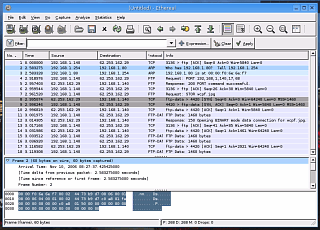 Ethereal
will now perform any calculations that need doing and
display it similar to the display on the right. Ethereal
will now perform any calculations that need doing and
display it similar to the display on the right.You should now be able to select a packet by clicking on it (look for one with 'POP3' in it) and then right-click on it and follow the stream. |
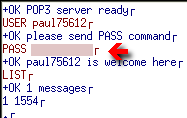 You should
now get something like the one on the right, with the
whole conversation colour coded so that you can see which
machine is talking (this screenshot is from a different
machine but it still uses Ethereal to do what is
described above). You should
now get something like the one on the right, with the
whole conversation colour coded so that you can see which
machine is talking (this screenshot is from a different
machine but it still uses Ethereal to do what is
described above).If your mail connection is encrypted, you should be able to select an unencrypted version to do this with but once you have your passwords, you should then be able to change them to new ones - something that you should do straight away. |
 If you
have just migrated to a new machine, it is fairly likely
that the last time you typed in your ISP account
passwords was so long ago that you cannot remember what
they were - you will need them so that you can access
your email via your POP3 account and you probably won't
be able to find that scrap of paper that you wrote them
down on several years ago (not that you should have done
that in the first place).
If you
have just migrated to a new machine, it is fairly likely
that the last time you typed in your ISP account
passwords was so long ago that you cannot remember what
they were - you will need them so that you can access
your email via your POP3 account and you probably won't
be able to find that scrap of paper that you wrote them
down on several years ago (not that you should have done
that in the first place).Infuriatingly incomplete dictionariesIf you use a particularly esoteric branch of English (say you work in a chromatography lab), you will be infuriated by the average spell checker's absence of knowledge when it comes to words in your field. But then, why should it know that 'Janak' (pronounced 'Yanak') is a primary chromatographic method used in cracking plant laboratories for the analysis of short chain aliphatic hydrocarbons from C0 to C4 inclusive and involves passing a carbon dioxide carrier gas down a molecular sieve column and absorbing the column's eluant in a potassium hydroxide solution in a special, inverted burette with an adjustable thistle funnel and therefore is a correctly spelled word? (Don't get me started on Zeisel analysis of methoxyl cellulose.)
Unfortunately, English is comprised of many ways of saying the same thing - it is manifestly clear that this is patently obvious - if you get my point. As a result, when you add up all of the variants of words that we use, the total runs into several million words. In everyday language, people tend to use around 40,000 words which means that they are only ever likely to use around one per cent of a truly complete dictionary. Looking at it another way, you will have all of that memory sitting there, with data in it and only around 1 per cent of it will be used. Of course, you could argue that as almost everybody completes all of the word processing work that they are ever likely to do by using only 1 per cent of the capabilities of a word processor such as MS Word, this is already a principle that is accepted. Another way of looking at it is that with so many ways to type in the wrong word, the end-users will be spoilt for choice when it comes to selecting the right one. Possibly for the reason that people don't bother to pronounce words properly, there are a number of words that people have no idea about such as:
Then, there are words that are spelled the same but have different meanings (therefore leading the user to think that there should be two different spellings) such as:
Being stuck with a semi-literate user population that is influenced by Americanised English and likely to click on the first alternative spelling they see because they don't know any better, the best you can do when you have installed your new word processor is to write a document that you know contains all of the correct spellings for your own field of work and then add them to your custom dictionary. |
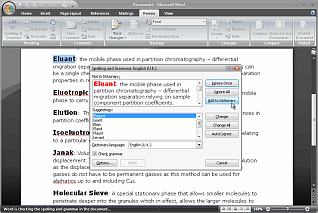 When spell
checkers originally came out (my first one was for the
Sinclair QL in the mid 1980s), they were deemed as the
end of people being able to spell. As word processing on
the PC became something that happened whilst you were
typing rather than something that happened at the end, it
became a game that you would deliberately spell a word
correctly so as to spite the spell checker - every
correctly spelled word was a battle won. However, spell
checkers are not complete.
When spell
checkers originally came out (my first one was for the
Sinclair QL in the mid 1980s), they were deemed as the
end of people being able to spell. As word processing on
the PC became something that happened whilst you were
typing rather than something that happened at the end, it
became a game that you would deliberately spell a word
correctly so as to spite the spell checker - every
correctly spelled word was a battle won. However, spell
checkers are not complete. Connect with CurlSometimes, if you are trying to find out what information is being exchanged when you connect to a http server, clicking on document properties in a browser is just not good enough - at best this only gives a summary of what actually occurred.
Curl is a client to get documents and files from a server (although it can send them as well) and can work with a number of protocols. There are many options with curl and to see them all, use 'man curl' To see a full ascii trace dump to STDOUT, use the '--trace-ascii' switch and to see more of the data that is exchanged between the client and the server, use the '-v' option. So, if you want to know what, for example, Google's server does, enter... curl -v --trace-ascii - http://www.google.com/ ...and see what happens. |
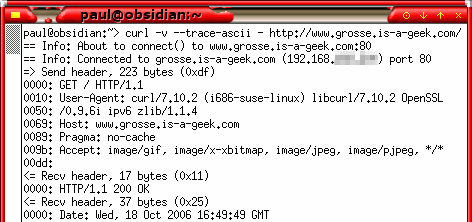 Even wget
only saves the file that was requested and whilst it
keeps the original file's date/time stamp, it still only
saves the file and optionally a log which still might not
provide the information you need.
Even wget
only saves the file that was requested and whilst it
keeps the original file's date/time stamp, it still only
saves the file and optionally a log which still might not
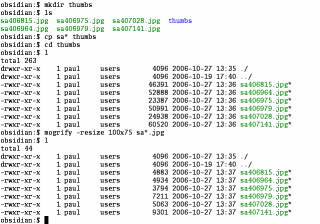
provide the information you need.Mogrify your imagesIf you have hundreds of thumbnail images to create or you want to update a collection of thumbnails automatically using a program such as a Perl script, you need a program that does the job perfectly (none of that messing around with GUI program rubbish - we're talking about good old efficient command line stuff here that you can get your computer to do for you without any supervision using a crontab at 4am on a Sunday morning). So, you have your photographs - say they all start with 'sa' as they do in the screenshot - and they live in the directory you want them to be in.
mkdir thumbs ...to make a subdirectory for the thumb-sized copies you are going to create. (it doesn't have to be called 'thumbs', you can call it anything you like). You can type 'l' to see the listing of the files. Next, copy your images (which here, all start with 'sa') into your 'thumbs' directory by typing... cp sa* thumbs .. and then... cd thumbs ...to go into it. If you type 'l', you can see your files. Now, type... mogrify -resize 100x75 sa*.jpg' to create your small images - note that this overwrites the originals in the thumbs directory (which is why we copied them to here in the first place) although you can use options with mogrify to make it write new ones. If you just type 'l' again you will see the file sizes of the new files. |
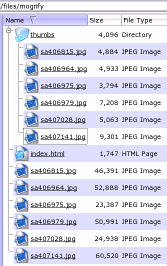 In the
Konqueror file browser, you can right-click on an image
file and click on properties. Under the 'Meta Info' tab,
you can see the dimensions for the new image as being 100
x 75 pixels. In the
Konqueror file browser, you can right-click on an image
file and click on properties. Under the 'Meta Info' tab,
you can see the dimensions for the new image as being 100
x 75 pixels.In the screenshot on the right, you can see just from the file sizes that the new files in the 'thumbs' directory are a lot smaller, having been processed by mogrify. |
 Just to
allow you to see the sort of quality you can get from
this program, I have assembled a web page of the
thumbnails that you can click on to show the original it
was derived from in the window below on the page. Just click here
to open it up in a new window. Just to
allow you to see the sort of quality you can get from
this program, I have assembled a web page of the
thumbnails that you can click on to show the original it
was derived from in the window below on the page. Just click here
to open it up in a new window.You can, of course, write a Perl script that not only mogrifies any new images that you give to it but also updates a web page that displays them - see the 'unicodegen' file mentioned above. |
 Open up a
console in the directory containing your originals and
type...
Open up a
console in the directory containing your originals and
type...Bathtub failure modelIf you've just bought a new computer and wonder how long you should leave it before reformatting the old one then you shouldn't put too much weight onto the MTBF value - especially when deciding that the new one has been going long enough for you to be confident enough in it to format the old machine and use it for something else (such as a home network file server). There are a number of things that can make a new computer (or anything for that matter) fail at a given time. At the beginning of its life, it is most likely to fail because of poor workmanship or material defects - this is given the poor-taste name 'infant mortality' (yes, honestly). As time goes on, parts start to fail because they wear out - the time between these two types of failure is called the 'useful life'.
The MTBF is the 'Mean Time Between Failures' and is often misinterpreted as the amount of time it will take for a component (such as a disc drive) to fail through old age. The MTBF applies to the normal life (roughly flat) part of the curve and is 1/failure rate. As a result, it can have values of 500,000 hours whereas the hard drive will have worn out through old age well before the end of this 57 years. A MTBF of 500,000 hours only means that 1.75 per cent of your drives will fail each year during the 'useful life' part of its use. Long before the 57 years is up however, the wear-out failure mode soon becomes dominant with its own, higher failure rate. It would, in all honesty, be more useful if the manufacturers gave you the time that the wear-out failure rate overtook the normal life failure rate as this is when you want to budget for replacing machines. So, is there a set time when you can reformat your old machine? No is the answer. All you can do is to make sure that you have an additional backup (remember that it is not a back-up unless there are two copies) of your data and keep the old one going until you feel confident that all of your favourite programs work on the new one. |
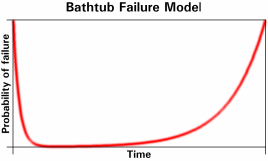 You can
see from the diagram on the right that the resulting
curve from the sum of these effects has the shape of a
bathtub and is actually called the 'bathtub failure
model'. Infant mortalities are (or at least should be)
unacceptable for the companies that build computers
because they produce the 'dead on arrival' stories that
we read about so often in magazines. However, it is
fairly easy for a company to remove these failures to a
large extent by 'soak-testing' them (aka 'burn-in') once
they are built. This soak-testing should take the
computer through a large portion of the infant mortality
period and hopefully, the end user is sold a machine that
will not fail until components wear out some years later
(hint: look at the length of the warranty for a clue as
to how long this is).
You can
see from the diagram on the right that the resulting
curve from the sum of these effects has the shape of a
bathtub and is actually called the 'bathtub failure
model'. Infant mortalities are (or at least should be)
unacceptable for the companies that build computers
because they produce the 'dead on arrival' stories that
we read about so often in magazines. However, it is
fairly easy for a company to remove these failures to a
large extent by 'soak-testing' them (aka 'burn-in') once
they are built. This soak-testing should take the
computer through a large portion of the infant mortality
period and hopefully, the end user is sold a machine that
will not fail until components wear out some years later
(hint: look at the length of the warranty for a clue as
to how long this is).The Registry - time to goMany years ago, Windows file systems used FAT (File Allocation Table) and over the years, Windows grew and grew, as did the hard drives. One of the limitations of FAT is that there are only a certain number of files that you can save (as there are with any file system although the number was lower with FAT) and as the storage devices get bigger, the clusters (effectively a number of contiguous blocks that forms the smallest usage of disk space a file can have) grow out of all proportion (a 64kByte cluster to hold a 100byte file). In effect, most of the drive space is wasted if you have a lot of small files. So, if you have a lot of programs and each needs a small configuration file (some of this data might be values relating to the position on the screen of a window and some of it might be important information that is critical to the running of the whole system and only the admin account should really have access to it), you are soon going to run out of space.
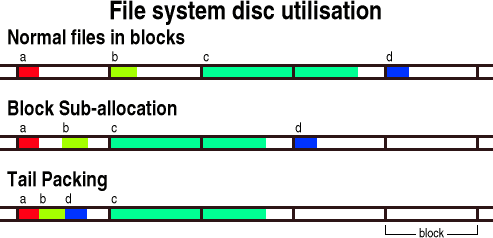
So, file systems move on and now, we have some systems that will use single blocks (usually 512Bytes) rather than clusters of them (for example, a 2.1GB HDD with FAT32 will have 4kB clusters so a 1 byte file will take up 4kB of disc space and on average, 2kB will be lost for each file that is saved). However, there are some things that file system developers can do to make file systems more effective. Some file systems will nominally divide a block into a number of divisions so that the last block used can have some of the space used by files that are less than a block long (actually, if you have 4 sub-blocks in a block, you can only save files that are less than 3 blocks long in this way if you think about it). NTFS partially supports block sub-allocation so it is getting part of the way there. One thing to note is that if a file is more than one block long, it has been found to be more efficient if that file starts at the beginning of a block (as in the diagram) - the end can still be packed if the file system's disc utilisation allows it. One limitation is that if you only have 4 sub-blocks per block, you can only store 4 files in each block. A further improvement on this is 'tail-packing' where effectively the minimum sub-block size is 1 byte. In this way, if your block size is 4kBytes long, you can store 40x100 byte files if you want. This is the most efficient as you can read many files at the same time if they are all in the same block - such as a load of gif files in the case of a web server or a load of config files. Tail packing is used in ReiserFS and in Reiser4 thus making them fast and efficient - suitable both for home machines and web servers. So, if the Registry is, in effect, a single point of failure, why are we still using it? |
 The
solution to this (or at least the most rational
explanation for this) was the creation of the Registry.
This is a single file that can store all of the really
important information that the system needs in order to
function properly as well as that equally important
information of where on the screen the minesweeper game
was when it was played last. Why are these equally
important? Simply because either of them can corrupt the
other's data simply because it is all stored in the same
file.
The
solution to this (or at least the most rational
explanation for this) was the creation of the Registry.
This is a single file that can store all of the really
important information that the system needs in order to
function properly as well as that equally important
information of where on the screen the minesweeper game
was when it was played last. Why are these equally
important? Simply because either of them can corrupt the
other's data simply because it is all stored in the same
file.Clean your printerWhen cheaper printers break, it is often easier (although environmentally reprehensible) to replace the printer. However, if you have a good quality office printer, you could well be looking at a machine that is getting on for 10 years old.
Cleaning older printers is often more like gardening than IT - there are piles of dried out ink and snow drifts of paper powder as well as loads of dust. In addition to this, the rubber that the wheels are made from is approaching the end of its useful life (might only be another five years in it so get saving for your next printer). There is, however, one wheel that is more important than the others and that is the one that takes up the paper. All you need to do is dismantle the front of the machine (with this Hewlett Packard, it is just a matter of reaching under the front of the paper delivery unit at the front and squeezing a pair of levers together sideways then pulling the unit out), exposing the wheels as in the photograph. Next hold down the form feed button. You should be able to see the wheel as the one with all of the extra levers and springs on it. Whilst it is moving, push a wet kitchen cloth up against it several times to remove the gunge (although you should be ready to pull the plug on it should something go wrong such as you get something trapped in there - remember that they are strong). Don't use anything stronger than water because this could damage the rubber. Reassemble the printer and it should work better. You could get another five years out of your printer. |
 In the
bathtub failure model (see above), a machine that is this
age is clearly starting to wear out and might not be
picking up sheets of paper as easily as it used to.
However, not all is lost.
In the
bathtub failure model (see above), a machine that is this
age is clearly starting to wear out and might not be
picking up sheets of paper as easily as it used to.
However, not all is lost.
|
 Final
Warning - Hardware peripherals - Taking Care
Final
Warning - Hardware peripherals - Taking Care