PC Plus HelpDesk - issue 250
This month, Paul Grosse gives you more insight into
some of the topics dealt with in HelpDesk
|
 |
HelpDesk
Secured communications on web browsers
If the protocol part of the address in the address bar starts with 'http://', the information will have been sent to you in the clear via port 80 (or 8080 or a similar port) - that is to say that there will have been no encryption and everything that you see in your web browse when you look at the source code will have been easily readable by anybody on the route (including anywhere on your subnet) with a packet sniffer. If the protocol part of the address in the address bar starts with 'https://', the information will have been sent to you encrypted via port 443 (Secure Sockets Layer or 'SSL') - that is to say that encryption keys will have been exchanged between the browser and the server in a reasonably secure way and the transmission of the page content from the server to the browser will have been pretty much what you can see in the image on the right. However, the protocol used for the current page does not necessarily represent that used for the next one. You can have your browser configured so that it warns you when you are about to send information across the Internet in the clear but it is too easy to turn that off and forget that it is off. So, how do you know that the protocol that will be used to transmit your data to the server will be sent via SSL? In the status bar at the bottom of the browser, you should be able to see how the link translates as you hover the mouse over the link part of the rendered page in the browser. However, if you are using JavaScript on the page and it is not a plain link, (ie, it is a button or a graphic - some web designers think that they are being clever when they use graphics for this but they are just undermining what little security that there is left on a browser) you might just see a JavaScript program link such as some function or other. In other words, you don't know and there is no way of telling just by looking at the rendered page. |
 One thing you could do is to work your way
through their code but life is too short for that and if
you could actually work out what it was trying to do, you
might even find a few errors. One thing you could do is to work your way
through their code but life is too short for that and if
you could actually work out what it was trying to do, you
might even find a few errors.Another way is to evaluate the site by setting up a sheep-dip account on your computer (ie, no special privileges, not in the same user group as your other accounts and so on) and then, whilst monitoring the web traffic by using a packet sniffer, use a prototypical account. For example, some websites suggest that you use your email address and a PIN to access your account information. So, instead, use 'securitytest@testdomain.com' and the PIN '1234' and click on the link. If you see any of that in your packet sniffer, you will know that the page is not secure (if you can sniff it, anybody else can as well). Some sites claim to be '100% secure'. However, there are a few things that will prevent them ever from being 100% secure. Some of these are:
This list is by no means exhaustive but it is a guide. |
 We
all know that if a website is being honest, the page you
are on should have been retrieved via either port 80 or
port 443.
We
all know that if a website is being honest, the page you
are on should have been retrieved via either port 80 or
port 443.Controlling services
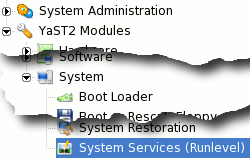
You can do this by going into Control Centre in SUSE Linux and under 'Yast2 Modules', 'System', 'System Services (Runlevel)', stop and start them from there. |
 Just
select 'Expert Mode' and select the service you want. Just
select 'Expert Mode' and select the service you want. |
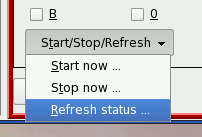 Next,
click on the 'Start/Stop/Refresh' combo and click on
'Stop now ...', then click on 'Start now ...' and that is
all you have to do. Next,
click on the 'Start/Stop/Refresh' combo and click on
'Stop now ...', then click on 'Start now ...' and that is
all you have to do. |
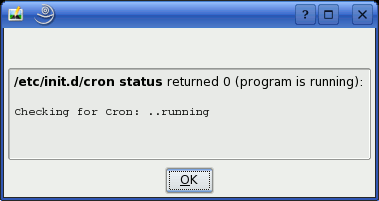 When each
action is done, you will get a little dialogue box like
the one on the right. When each
action is done, you will get a little dialogue box like
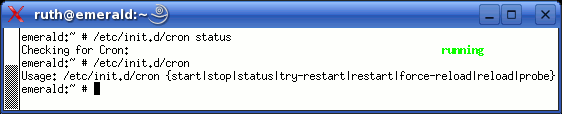
the one on the right.However, there is an easier way of doing this and there are more options. So, how do you do it and what are the options? If you look at the dialogue box, you can see that the top line starts off with... /etc/init.d/cron status and that is the clue. It is a command that you can enter from the command line. In /etc, there are a number of directories as well as other configuration files. The init files are in the init directory which has the extension (as so many have in order to distinguish them from files) of '.d'. In there ('/etc/init.d/'), you can find the running scripts for the services that are available on the computer. The thing about these is that they are scripts and unlike the opaque binaries that you will find on OSes of the likes of Windows, you can actually load these into a text editor and look at them Here is a snippet from the cron file and you can see the sort of thing that is in there (this is just a case section and it is the catch-all part that goes at the end)... case "$1" in <snipped out loads of programming here> *)
echo "Usage: $0 {start|stop|status|try-restart|restart|force-reload|reload|probe}"
exit 1
;;
esac
You can see that this is the usage section and you can see the options. Apart from 'start' and 'stop', there is also: 'status' (which is that the runlevel editor has been using); 'try-restart'; 'restart'; 'force-reload'; 'reload'; and, 'probe'. That is just for the 'cron' program. These options vary from program to program and it is easier to open a console and type the following. |
 |
 One of the
nice things about Linux, the BSDs and other UNIX-like
OSes is that you can stop and start services without
having to reboot the machine.
One of the
nice things about Linux, the BSDs and other UNIX-like
OSes is that you can stop and start services without
having to reboot the machine.'Hello World' html documents
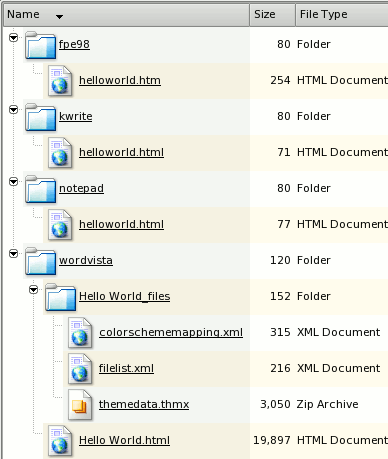
However, everybody knows that the tightest html code comes from editors such as KWrite (71 bytes for 'Hello World') or NotePad (77 bytes) with specially designed html editors producing code that is close: for example, FrontPage Express 98 produces a file of 254 bytes. However, in the same test, Microsoft Word running on Windows Vista produced a html file of 19,897 bytes along with an extra 3,581 bytes in three files in the document's very own subdirectory (and it commits the faux pas of having file names with spaces in them). That is a total of 23,478 bytes and that doesn't include the directory metadata which will, of course, depend on what file system you are using. You can make up your own mind about which is more efficient. If you click on the image on the right, you can open up the directory so that you can look at the html coding for yourself. Note that the only difference between the Notepad and KWrite examples is that one has line endings in UNIX style and the other in DOS style. |
PDF file sizes
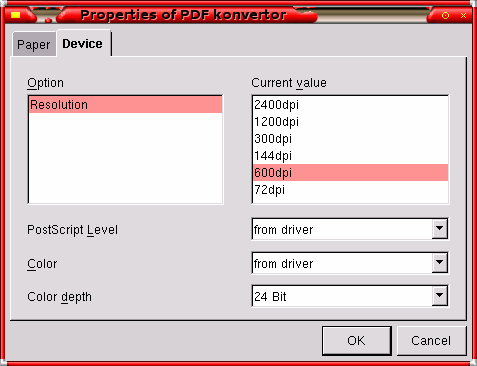
However, there are one or two things to consider. One of these is that the high quality of text output is a result of the format being based upon vectors -- in the same way that PostScript files are. In this way, a document can be printed out at A6 size and A0 size and the curves and other details in the font are just as accurate as each other (in absolute terms). A problem with this is that images tend to be based upon pixel maps where each point is given a value and each point is independent of each other. As a result, a highly detailed image can be modified so that it produces a substantially smaller file if the end result only needs to be displayed at, say 144dpi (blown up slightly on a monitor) instead of its original 2,400dpi. |
 Choosing a
setting for images does not affect the size of a
text-only file but for one that contains images, it can
mean the difference between a website file of 50kB and
20MB. Choosing a
setting for images does not affect the size of a
text-only file but for one that contains images, it can
mean the difference between a website file of 50kB and
20MB.The image on the right is of a PDF file that you can open up by clicking on it - it is my original text and image for the often (certainly in this case) satirical 'Hypotheticals' section published in the magazine. Produced for the Internet, this version weighs in at just 149,642 bytes and was printed on OpenOffice.org. |
 Look at
the detail in the image as you zoom in on it and compare
that with the text that is next to it. Look at
the detail in the image as you zoom in on it and compare
that with the text that is next to it.On the right you can see that smaller file sizes can be achieved in two ways - one is to adjust the size of the pixels in the final image and the other is to use compression such as JPEG compression. For web purposes, both of these can be used to make quite small files that do the job well (you didn't really want only 3 lines of text to fill the screen, now, did you?) |
 PDF
(Portable Document Format) is a very popular format on
the Internet because it allows your layout and fonts to
remain the same in a given document, regardless of the
environment that the document is viewed in. As a result
of this - and the PDF format being an open format - many
word processors can either print to PDF or export to it.
PDF
(Portable Document Format) is a very popular format on
the Internet because it allows your layout and fonts to
remain the same in a given document, regardless of the
environment that the document is viewed in. As a result
of this - and the PDF format being an open format - many
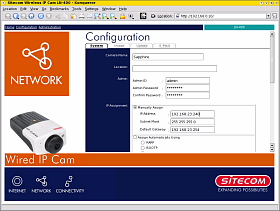
word processors can either print to PDF or export to it.Getting network devices onto your subnetMany IP devices arrive with static IP addresses already assigned to them although these are rarely on the subnet you use. Whilst it might seem easier if they allowed DHCP to assign an address to it, if you haven't got a DHCP server on the physical network it is plugged into, you are potentially in a worse position. Some of the manufacturers occasionally provide a program that will find the device on your network for you and allow you to configure it but you are restricted to the OS and version (usually just Windows) and they only do what you can do for yourself here any way.
So, first of all, you need to get a spare computer (say that this spare machine's IP address is 192.168.23.163) and change its IP address so that it is on the same subnet as indicated in the device's instructions. You can only do this with admin rights so first of all, you need to su to root. Next, give it the address 192.168.0.1 by using... ifconfig fxp0 192.168.0.1 ...if you are on BSD, or substitute 'fxp0' with 'eth0' on Linux or 'hme0' on Solaris. Note that you might need to use a different number or, if your Ethernet card is of a different type (say a PCMCIA card or on a USB port), you might end up using something completely different. If you are uncertain, just type... ifconfig -a and you will see the interfaces that are available. |
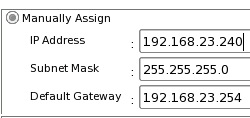
 Now that
your browser can communicate with the device, you can
call up the web browser and change its subnet Now that
your browser can communicate with the device, you can
call up the web browser and change its subnetYou need to change the default IP address so that it resides within your network's subnet - in this case 192.168.23.0/24. |
 When you
click OK, it will change it's IP address so that it is on
your normal subnet (or at least one that you have a
defined route to). When you
click OK, it will change it's IP address so that it is on
your normal subnet (or at least one that you have a
defined route to).Clicking on OK in the browser will mean that unless you get onto the same subnet as it, you will not be able to communicate with it so make sure that you have the correct IP address assigned to it otherwise you are either in for a long search through the IP address ranges you could have typed in by accident or you will have to go and press the factory reset button which is most likely on the back of the unit itself. |
Now, go back to your console and use ifconfig with
your computer's original IP address so that it now
resides within your network's subnet. Use...ifconfig fxp0 192.168.23.163 ...with the same provisions as before. |
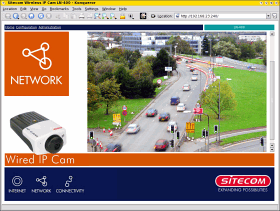 Now, you
can use the network device's new IP address and continue
with the configuration. Now, you
can use the network device's new IP address and continue
with the configuration.Note that all of the time you have been doing this, you haven't needed to rewire your network because the switches can cope with several subnets on the same physical network. |
 Many of
these devices are configurable through a web browser
interface but if you type the IP address (say that it has
a default IP address of 192.168.0.10), you will not get
anywhere because there is no route between its subnet and
the one you are on (say, your subnet is 192.168.23.0/24).
Many of
these devices are configurable through a web browser
interface but if you type the IP address (say that it has
a default IP address of 192.168.0.10), you will not get
anywhere because there is no route between its subnet and
the one you are on (say, your subnet is 192.168.23.0/24).